Dans ce dernier billet consacré au projet Sudoc21, sont abordées les solutions informatiques choisies pour tester l’implémentation du modèle de données (format pivot) conçu par les experts de la modélisation bibliographique.
- Nom de code Sudoc21
- Les données en diptyque
- Retours sur l’exploration des solutions informatiques
A partir des différentes solutions logicielles permettant de stocker, interroger et mettre à jour les données structurées selon le format pivot, il s’agissait d’évaluer l’aptitude à traduire en terme de système d’information les différents cas d’usages, et notamment d’évaluer leur complexité technique et leur facilité d’implémentation. De manière générale, le volet « expérimentation des solutions informatiques » a constitué un espace d’échanges et de réflexion entre les membres de l’équipe Sudoc21, indépendamment du domaine de compétences de chacun, ce qui a renforcé la diffusion et le partage d’expertises.
Un projet tourné vers l’avenir
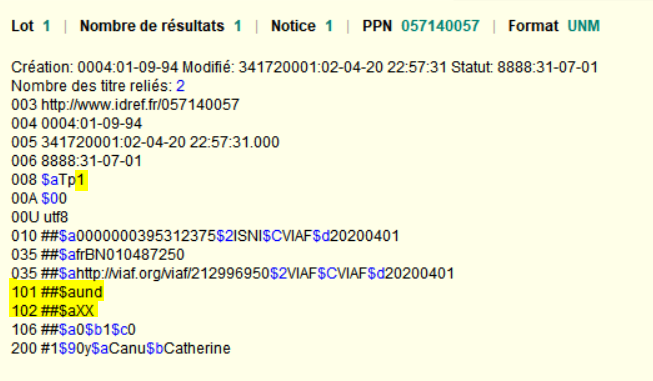
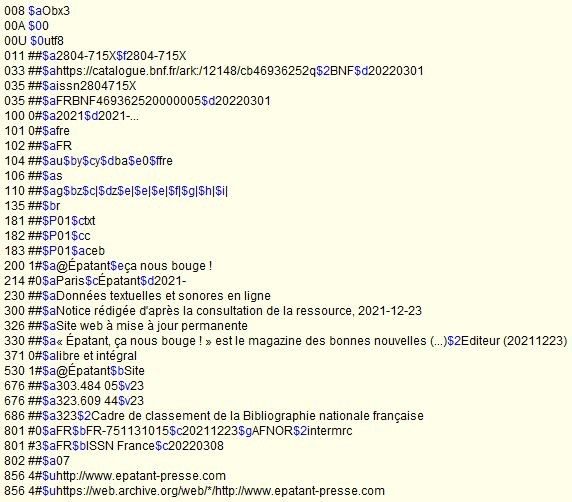
L’équipe informatique du projet Sudoc21 a conservé à l’esprit le fait que le système d’information va être amené à gérer des volumes de plus en plus conséquents : si, en l’état actuel, l’éclatement des données Sudoc en entités s’évalue en milliards, l’objectif est d’atteindre une granularité plus fine encore, comme en témoigne le « en deçà » (ie. chapitres, articles, numéros et volumes) évoqué dans le précédent billet Punktokomo à ce sujet : Les données en diptyque : exercice d’apagogie négative:
“Ce modèle a mis en exergue l’importance de la notion de “granularité” : en deçà, granularité de description documentaire – livres et revues, mais aussi leurs parties composantes -chapitres, articles, numéros et volumes”
Il s’agissait également de tenir compte des assouplissements à prévoir lors de la conception et de l’évolution des schémas de données.
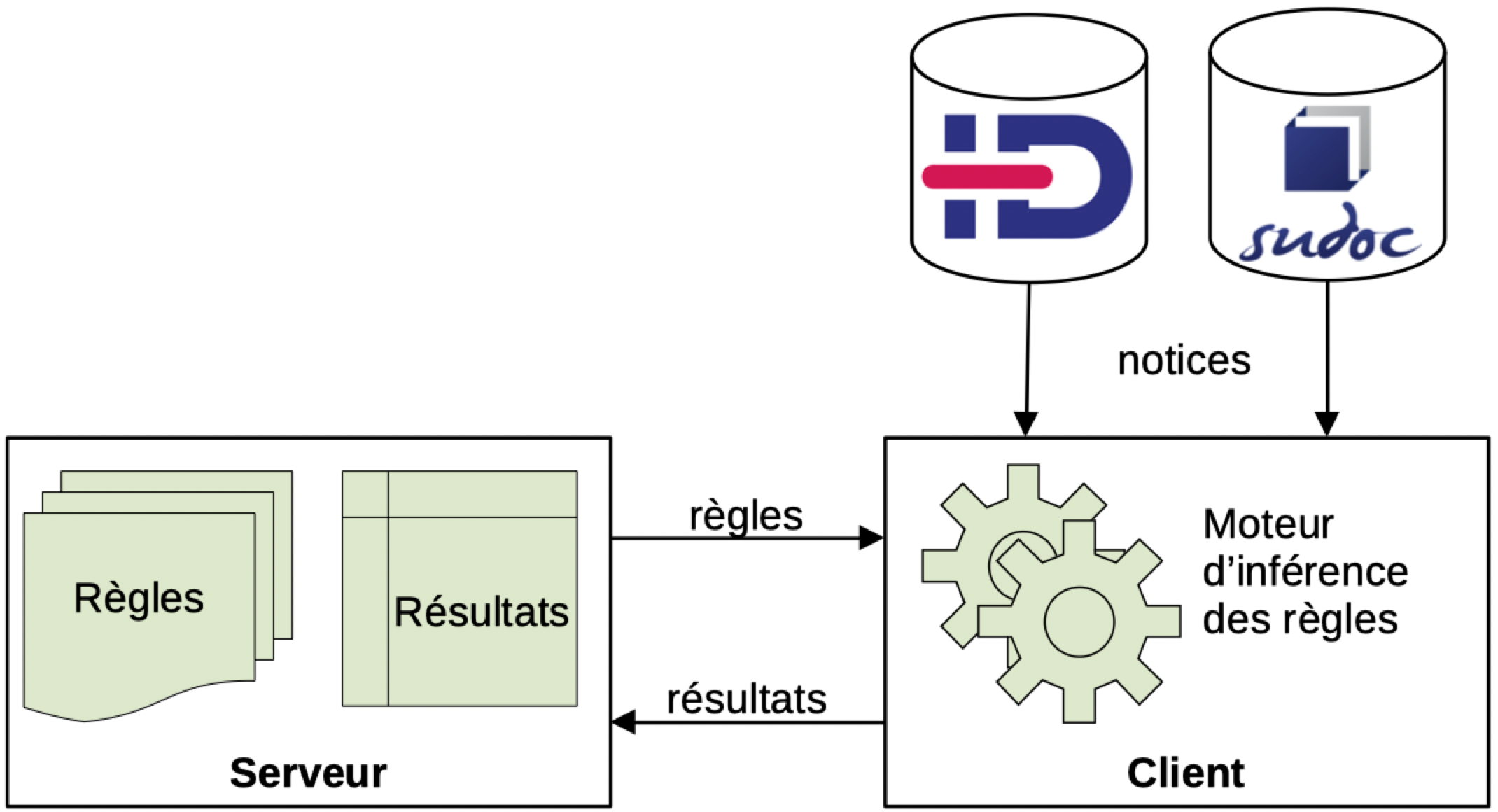
Pour prendre en charge ces contraintes, l’équipe a envisagé, en complément des solutions relationnelles classiques, d’autres solutions de stockage et d’interrogation, qui intègrent des mécanismes plus flexibles. Il existe en effet différentes possibilités techniques permettant :
- soit d’«éclater» des données dans une granularité très fine (« atomique ») – chaque instance pouvant avoir des relations différentes – et de les lier entre elles
- soit d’obtenir un compromis entre de la donnée « tabulée » – classique, relationnelle – et de la donnée « orientée » – composite et faiblement structurée- qui bénéficie peu ou pas des avantages d’un stockage en tables
Dans le cadre du projet Sudoc21, les explorations techniques ont donc été réalisées selon trois approches : une approche relationnelle classique, une approche « graphe » et une approche « mixte » (suite…)