
Ces billets sont la seconde partie d’une trilogie consacrée au projet Sudoc21. Ils reviennent sur les enjeux de la modélisation des données posés dans le premier billet, et sur la manière dont l’équipe en charge du projet s’y est confrontée.
-
-
- Nom de code Sudoc21
- Les données en diptyque
- 2- 1 Le noyau de la cerise ou la culture du pivot
- 2- 2 Exercice d’apagogie négative
- Retours sur l’exploration des solutions informatiques (billet technique)
-
Tout en cherchant à conceptualiser ce modèle cible, nous avons parallèlement exploré certaines logiques de modélisation, pour en évaluer l’intérêt, ou les écueils. Ces expérimentations nous ont conduits à des choix de modélisations parfois hétérodoxes, parfois même pas totalement cohérents, et ce volontairement. Voici quelques exemples de ces choix, des réflexions qui nous y ont menés et des leçons que nous en avons tirées.
Être ou ne pas être… un Nomen
Nous avons ainsi beaucoup joué avec les Nomens, qui dans le modèle LRM portent les appellations des autres entités, quelles qu’elles soient : titres, noms, libellés. Nous avons pris parti de les considérer comme des entités à part entière, ils sont donc vite devenus omniprésents. Seule entorse au principe, nous n’avons pas poussé cette logique jusqu’à faire des identifiants eux-mêmes des Nomens, comme ils sont censés l’être. Excepté, à titre expérimental, pour l’ISSN-L (ISSN de lien, attribué par le Registre ISSN, commun aux différents supports de publication d’une ressource continue).
Notre retour d’expérience sur ce point, après avoir travaillé sur les cas d’usages en écrivant des requêtes au cours de nos tests des différentes solutions, est mitigé. L’intérêt du Nomen comme entité, est de pouvoir en “dire quelque chose” en plus de sa valeur via des propriétés : langue, écriture, parfois sous-éléments (comme le nom et le prénom pour les personnes), données de gestion…
A contrario, les requêtes portant bien souvent sur la valeur littérale de ces entités, leur présence en « bout de chaîne » alourdit considérablement, à la fois l’écriture de la requête et le parcours des données.
Si c’était à refaire, nous reconsidérerions ce choix : il serait plus économique et efficace de les repenser comme propriété de leur entité mère, à condition de disposer d’un mécanisme permettant de qualifier cette propriété, comme nous l’avons fait pour les affiliations.
Agrégats à gogo
Les agrégats : ressources continues & cie
Nous avons, dans un premier temps, modélisé distinctement les « ressources agrégatives » (plus particulièrement les ressources continues). Chemin faisant, nous nous sommes rendu compte de l’inutilité de ce traitement particulier qui, entre autres, redondait les classes WEMI. En conceptualisant finement les ressources continues on gagnait aussi sur le terrain des agrégats relatifs au périmètre des monographies. Ainsi en homogénéisant le modèle nous avons pu constater que la notion d’agrégat était fondamentale car elle ne s’appliquait pas à un type d’entité particulier mais bien aux relations dites d’agrégations.
Les poupées russes
De plus, au moment de l’intégration des échantillons en RDF, nous avons dû mettre au clair l’architecture des relations qu’entretiennent les “monographies” ou les périodiques avec leurs “parties composantes” : articles, chapitres, mais aussi numéro et volumes.

Contrairement à la modélisation proposée en décembre 2018, nous avons choisi les manifestations, et non les expressions, pour relier les niveaux de granularité de publication : numéros et les volumes. D’autant plus que pour ces niveaux intermédiaires nous avons estimé superflu de créer une expression et une œuvre, dont nous n’aurions rien eu à dire dans la plupart des cas. L’architecture est similaire pour les chapitres de livres.
A noter également que nous avons choisi de considérer les versions électroniques et imprimées comme des manifestations et non comme des œuvres en série distinctes, contrairement à la notion de WEM-Lock prévu dans le code RDA. Ce choix non orthodoxe nous a permis d’homogénéiser notre modèle et de mettre à profit un des atouts du modèle LRM : la factorisation à un niveau supérieur des informations communes aux supports imprimé et électronique, en s’affranchissant de la scission entre “ressources continues” et “monographies” héritée du modèle non LRMisé.
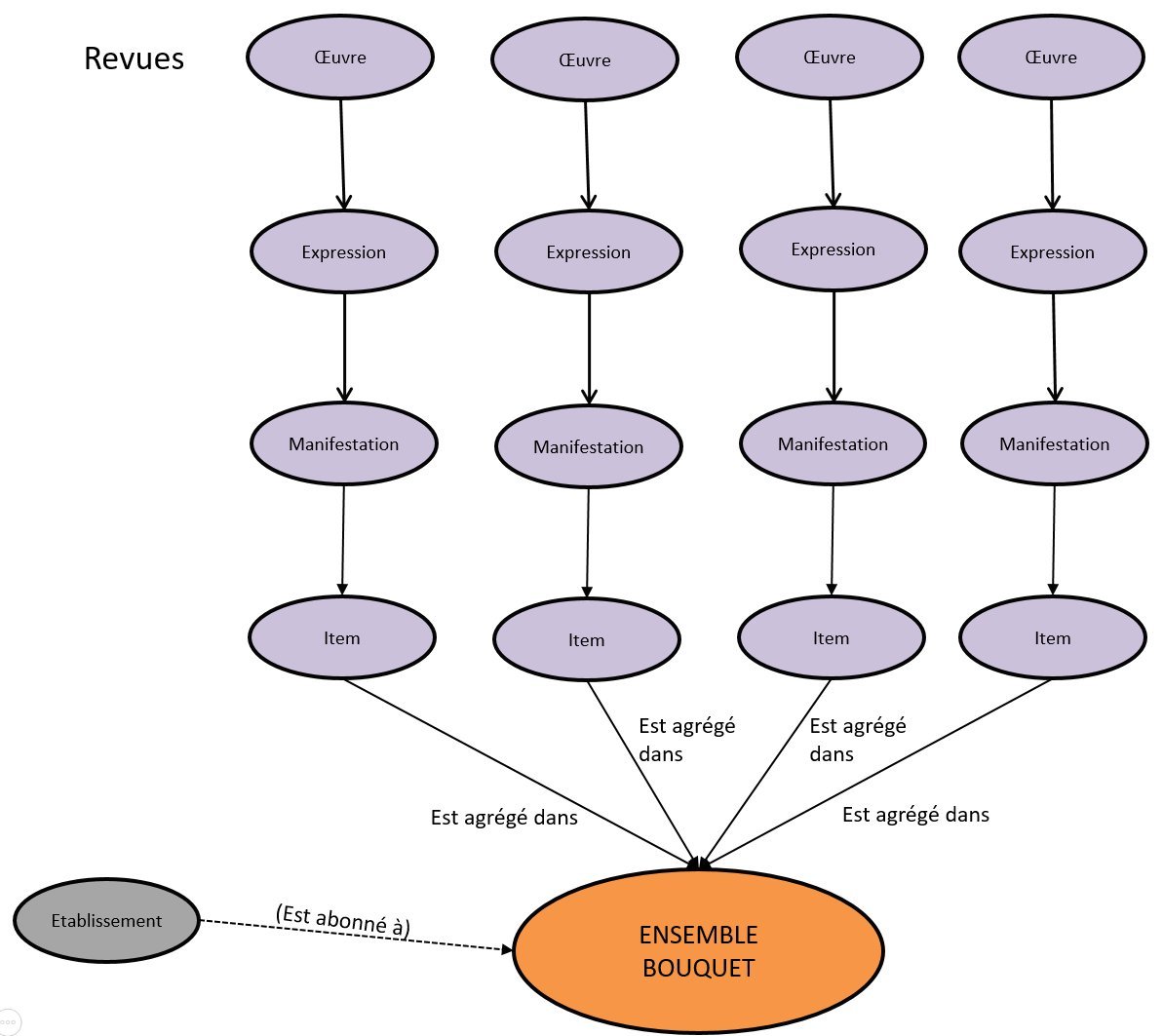
Extension du modèle : la classe Ensemble
Notre problématique de “pot commun” nous a conduits à travailler sur un autre type d’agrégat, qui ne semble pas trouver sa place dans le modèle LRM standard : les bouquets commerciaux de revues et d’ebooks, proposés par les éditeurs et signalés dans BACON par des fichiers Kbart.
Pour les décrire, et les connecter aux données du Sudoc, nous avons introduit une nouvelle entité très générique : l’Ensemble. Il est défini comme un regroupement d’entités du même type, ou de sous-ensembles d’entités du même type.
Sur cette base nous avons défini une sous-classe Bouquet, comme collection d’Items (ici points d’accès à une ressource dans le cadre du bouquet).
Nous avons ensuite réutilisé cette entité Ensemble pour modéliser deux autres cas : les Plans de Conservation Partagée des Périodiques (PCPP) et les fonds de bibliothèques.
Modélisation des affiliations
Version pré-existante : modélisation en RDF
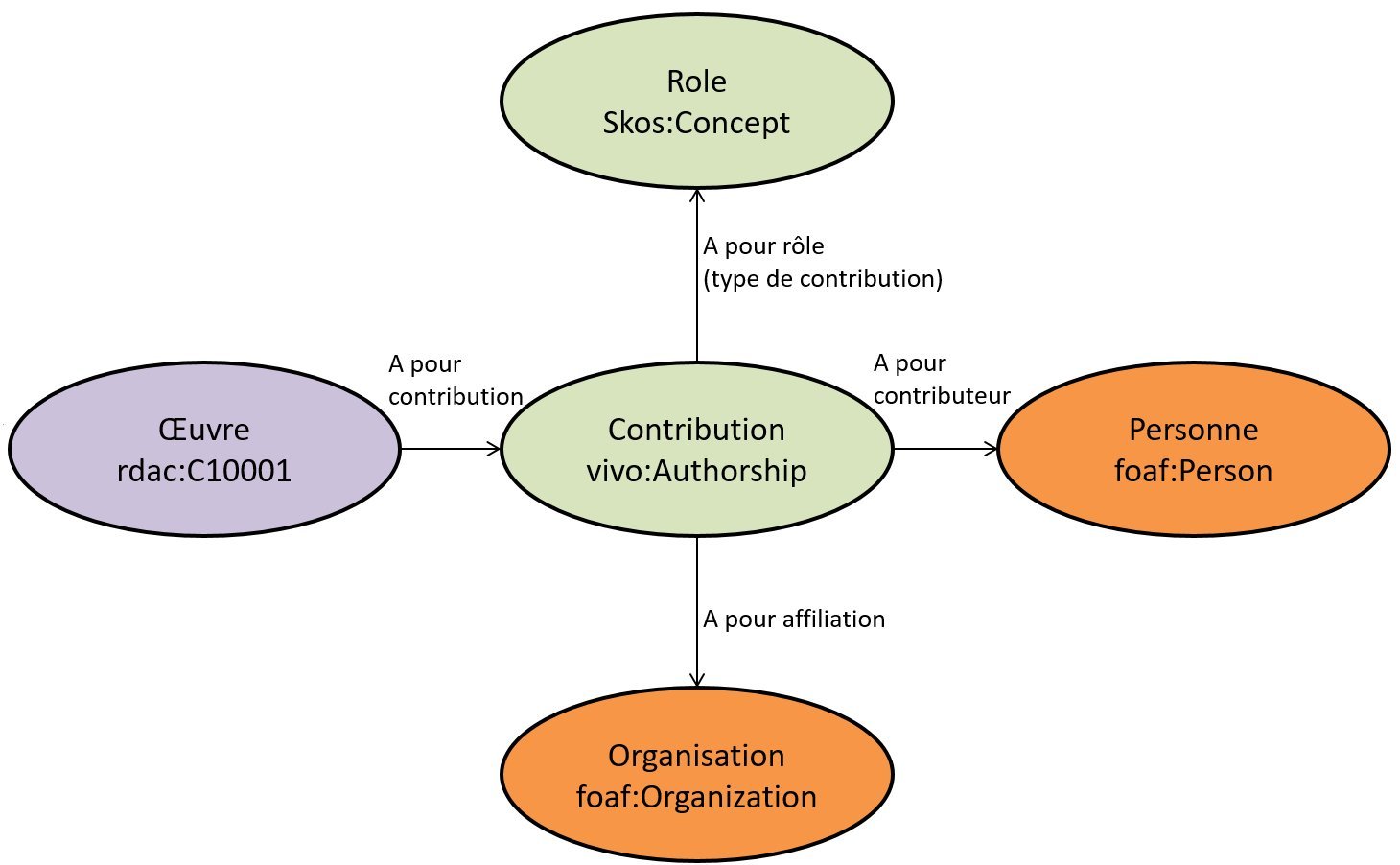
Pour les affiliations, nous avons travaillé sur les corpus acquis dans le cadre des licences nationales et des projets ISTEX et CollEx (depuis cette année partiellement chargés dans scienceplus.abes.fr).
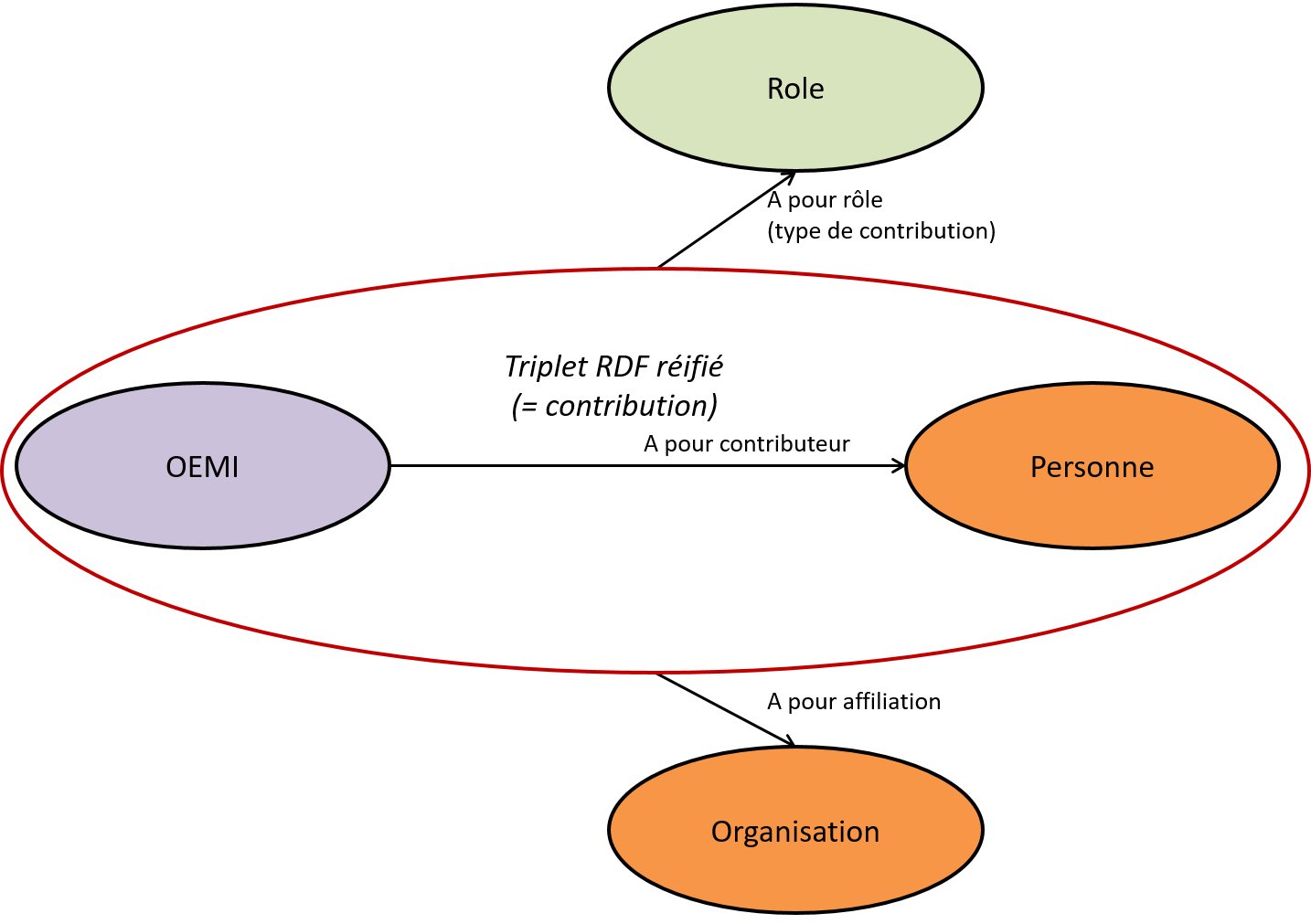
Ce modèle utilise un système de réification classique en RDF standard : l’insertion d’une entité intermédiaire (Authorship, ou Contribution) pour porter notamment la propriété “rôle” et surtout la relation d’affiliation.
Version Property Graph (Neo4j)
Requête Cypher qui renvoie, pour une thèse (niveau Œuvre), l’identifiant (uri idRef) et le Nomen de son auteur.
MATCH (n2:Nomen)<-[r2:A_POUR_NOMEN]-(a:Personne)<-[r3:A_POUR_CONTRIBUTEUR]->(o:Oeuvre) WHERE o.id='http://www.abes.fr/2015AIXM1096/w' and 'auteur' in r3.role and n2.typeAcces='paa' return o,r3,a,n2,n2.valeur
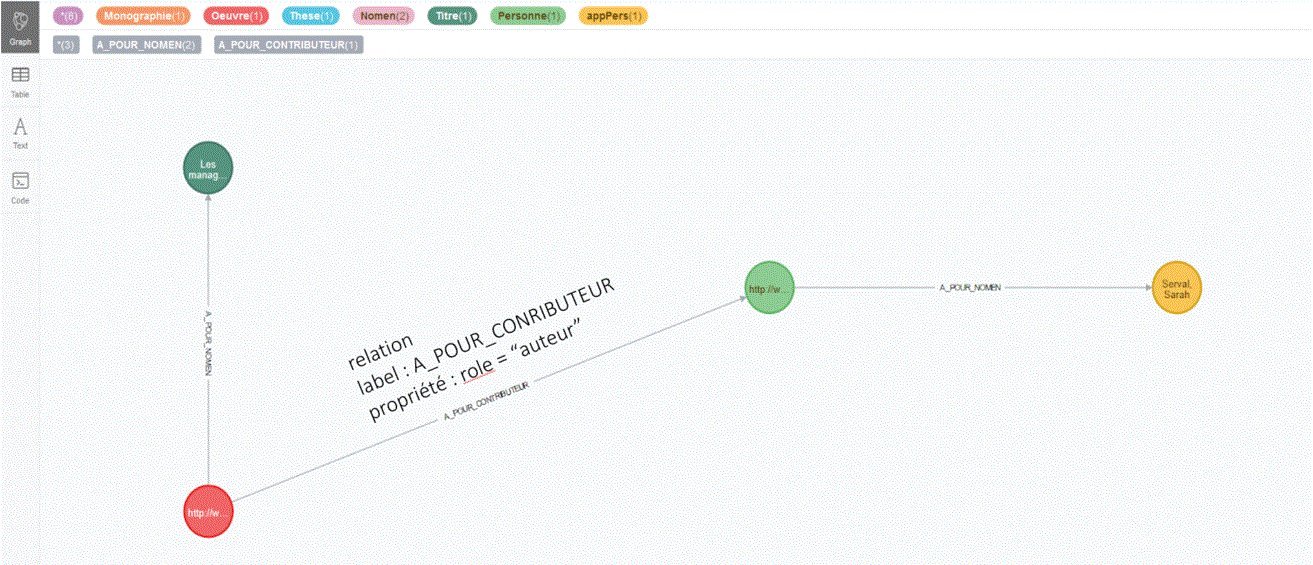
La réification n’est ici que partielle : la relation a_pour_contributeur porte ici la propriété “rôle” mais, comme le Property Graph ne permet pas de qualifier une relation avec une autre relation, il est impossible d’exprimer la relation d’affiliation. Par conséquent, il faudrait recourir à une entité intermédiaire pour porter cette relation comme en RDF.
Version base de données relationnelle (Oracle)
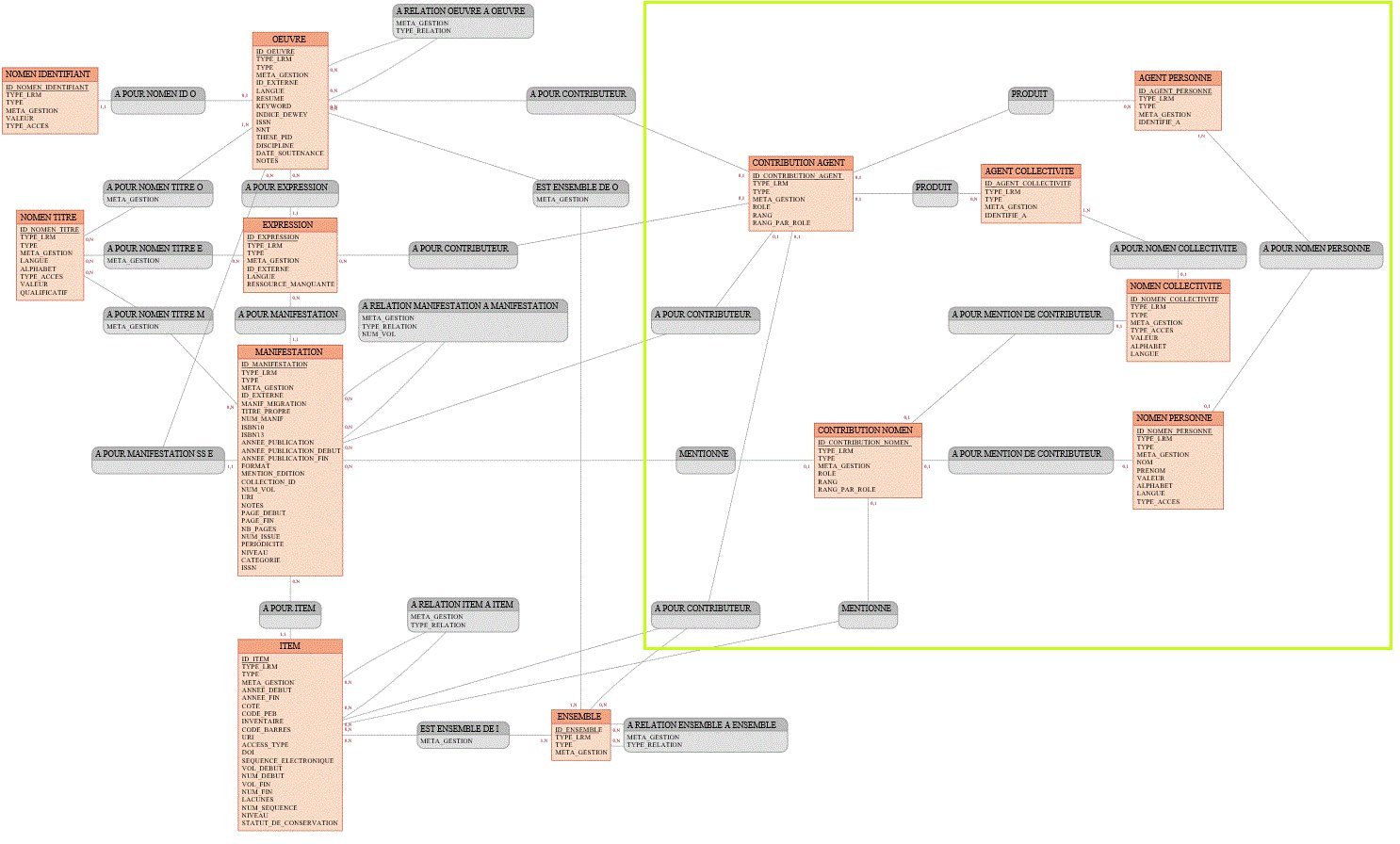
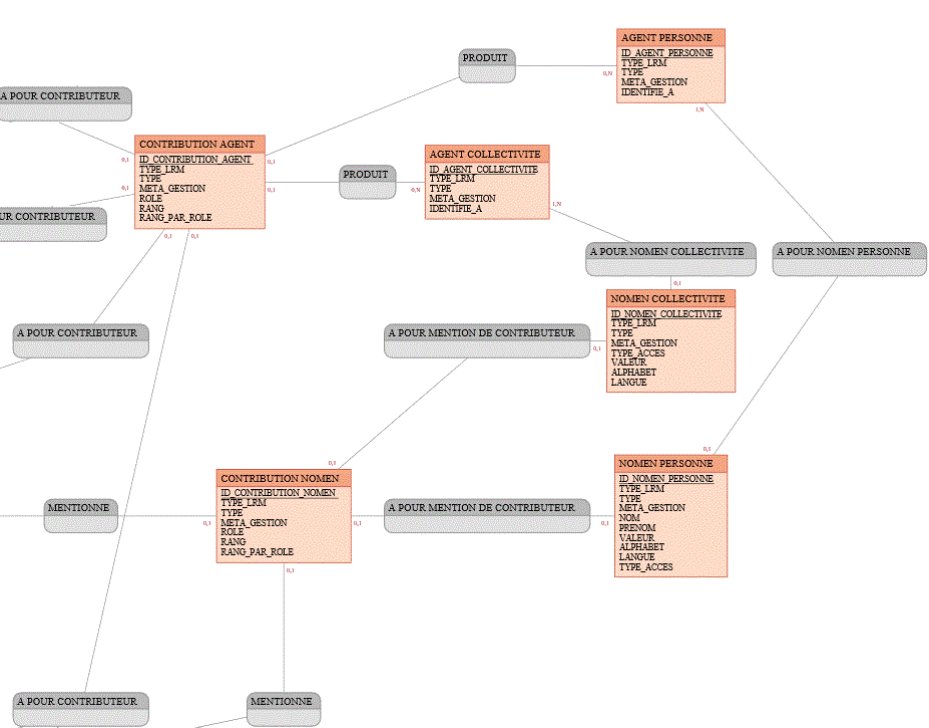
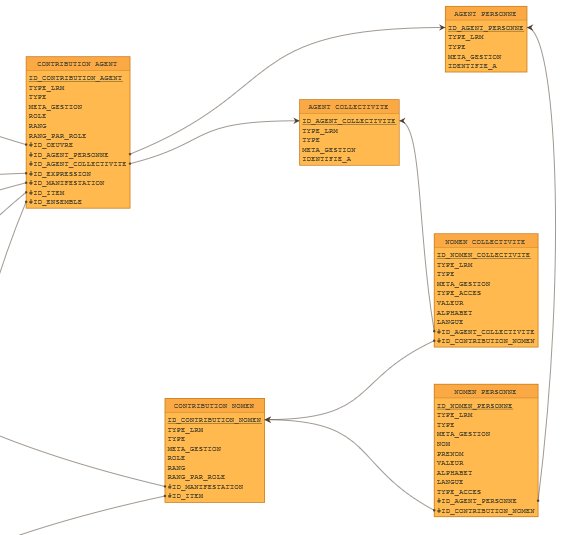
Afin de respecter les contraintes de cardinalités et d’intégrité, la modélisation en vue du stockage en base relationnelle nous a classiquement conduits à multiplier les tables intermédiaires ; ici pour le cas de contributions et de leurs affiliations l’insertion des tables CONTRIBUTION_AGENT et CONTRIBUTION_NOMEN.
Version RDF
Requête SPARQL* qui renvoie l’URI des œuvres, leurs(s) auteur(s) (nom + prénom) et leur affiliation
SELECT *
WHERE
{?oeuvre abes:a_pour_contributeur ?auteur.
?auteur abes:a_pour_nomen [abes:nom ?nom ; abes:prenom ?prenom].
<< ?oeuvre abes:a_pour_contributeur ?auteur >> abes:a_pour_affiliation ?affiliation; abes:role “auteur”.
?affiliation abes:a_pour_nomen [abes:valeur ?nomAffiliation].
}
LIMIT 100
Conclusion
Ce projet nous a permis d’expérimenter un modèle réconciliant des données bibliographiques, jusque-là “ensilotées”. Le format pivot isolant les grains d’information, il a été aisé de les manipuler pour les recombiner en entités LRM.
Ce modèle a mis en exergue l’importance de la notion de “granularité” :
-
-
- en deçà, granularité de description documentaire : livres et revues, mais aussi leurs parties composantes : chapitres, articles, numéros et volumes ;
- au-delà, le regroupement des ressources en bouquets, plans de conservation et fonds documentaires.
-
Cependant la réconciliation et la déduplication, étapes indispensables après génération des entités OEMI, pour atteindre notre “pot commun” n’ont pu être qu’ébauchées dans le temps du projet. Suffisamment toutefois pour mettre en lumière le saut que représente cette opération par rapport aux procédures actuelles de dédoublonnage ; il faut désormais raisonner sur des ensembles d’entités reliées et non plus, à l’instar des notices bibliographiques, sur des métadonnées cloisonnées.
Cette approche de “pot commun” ouvre les horizons pour construire de nouveaux services rationalisés et harmonisés autour de données réconciliées.
Ping : Les données en diptyque : le noyau de la cerise ou la culture du pivot [2-1] - PUNKTOKOMO
Ping : Nom de code Sudoc21 - PUNKTOKOMO
Ping : Projet Sudoc21 : retours sur l'expérimentation des solutions informatiques - PUNKTOKOMO