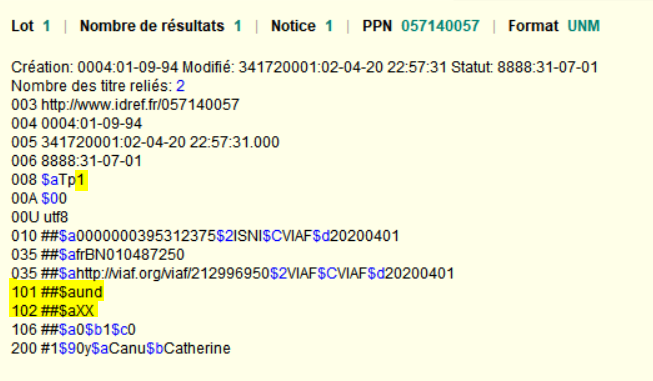
Anatomie des alignements à l’Abes (ou métaphore des chaussettes), épisode 3/3
Pour conclure la mini-série initiée avec les épisodes 1 et 2, voici une petite illustration récente d’un travail d’alignement (matching) à l’Abes.

L’alignement présente quelques similarités avec cette tâche rebutante qui nous revient avec la baisse des températures[1] : la corvée de chaussettes. Retrouver à chacun sa chacune, en fonction du nombre de personnes sous votre toit, peut s’avérer extrêmement fastidieux. Il y a les homonymes (Tiens, encore une chaussette grise ?), les faux amis (même modèle mais taille différente, 31-34 et pas 27-30), les singletons (ah oui, la gauche était trouée et est devenue chiffon) et les cas d’espèces (ah, cet étrange modèle dont un pied est orné de frites et l’autre d’une bouteille de ketchup mais qui forment une paire tout de même), et même les lèche-bottes[2]. Pour vous donner une bonne excuse pour procrastiner, lisez-donc la suite (et peut-être que vous verrez l’appariement sous un autre jour).