Alignement dans IdRef des contributeurs du catalogue éditeur de l’IFAO – Institut Français d‘Archéologie Orientale
 Sous la tutelle du MESRI – Ministère de l’enseignement supérieur, de la recherche et de l’innovation, les 5 Écoles Françaises à l’Étranger (EFE) – l’École française d’Athènes, l’École française de Rome, l’Institut français d‘archéologie orientale du Caire, l’École française d’Extrême Orient et la Casa de Velázquez – sont régies par un décret commun depuis 2011. Dans des aires géographiques et des domaines scientifiques propres à chaque école, les EFE ont pour mission de développer la recherche fondamentale sur le terrain et la formation à la recherche. Elles ont également une activité importante en tant que maison d’édition. C’est sous l’angle de ce pan d’activité qu’a été menée l’opération d’identification fiable et pérenne d’auteurs, objet de ce billet.
Sous la tutelle du MESRI – Ministère de l’enseignement supérieur, de la recherche et de l’innovation, les 5 Écoles Françaises à l’Étranger (EFE) – l’École française d’Athènes, l’École française de Rome, l’Institut français d‘archéologie orientale du Caire, l’École française d’Extrême Orient et la Casa de Velázquez – sont régies par un décret commun depuis 2011. Dans des aires géographiques et des domaines scientifiques propres à chaque école, les EFE ont pour mission de développer la recherche fondamentale sur le terrain et la formation à la recherche. Elles ont également une activité importante en tant que maison d’édition. C’est sous l’angle de ce pan d’activité qu’a été menée l’opération d’identification fiable et pérenne d’auteurs, objet de ce billet.
Depuis 2015, les 5 EFE ont lancé un projet de catalogue commun de leurs publications afin de favoriser leur visibilité à partir du site web commun aux EFE et de répondre à des besoins similaires de distribution. Pour construire ce catalogue commun, fédérant les 5 catalogues sous ONIX V3 et rassemblant au total environ 10 000 contributeurs, il est apparu essentiel d’identifier de manière univoque et pérenne les personnes sous les mentions d’auteurs, et par là même de désambigüiser les appellations homonymes – cas particulièrement courant dans les pays arabes.
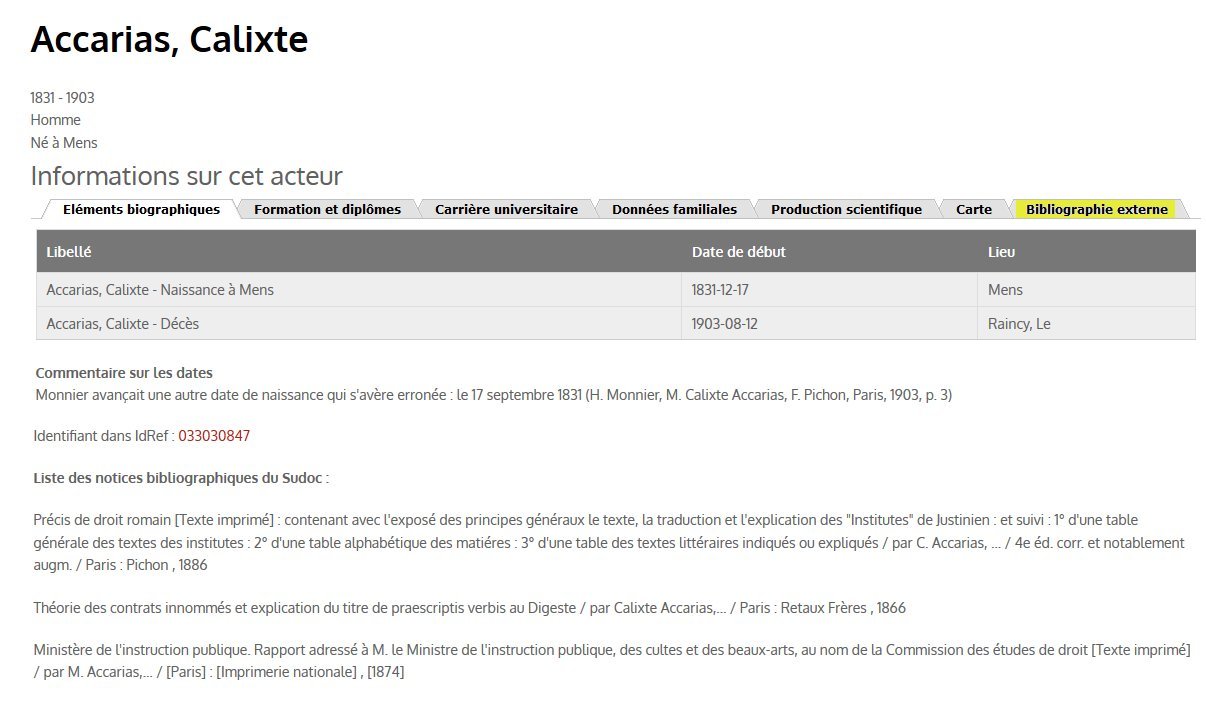
 Avec l’idée d’une méthodologie réplicable aux 4 autres EFE, il a été convenu que l’IFAO du Caire initie cette tâche en s’adressant à l’Abes pour l’aider à aligner les contributeurs IFAO avec le référentiel IdRef.
Avec l’idée d’une méthodologie réplicable aux 4 autres EFE, il a été convenu que l’IFAO du Caire initie cette tâche en s’adressant à l’Abes pour l’aider à aligner les contributeurs IFAO avec le référentiel IdRef.
Une perspective plus globale encore est de disposer à terme d’une identification pérenne de l’ensemble des acteurs de la recherche dans les EFE, qu’ils aient contribué aux publications (imprimées ou électroniques), aux bases de données documentaires en ligne, aux archives scientifiques ou aux travaux en cours.
 En complément du billet Fil’Abes au sujet de
En complément du billet Fil’Abes au sujet de