
En 2025, le SCD de l’université Lyon 3 s’est lancé dans la mise en place d’un connecteur Sudoc afin d’enrichir l’outil BiblioRef, logiciel bibliométrique et bibliographique open source développé par l’établissement.
Pourquoi BiblioRef ?
Dans son rapport d’évaluation 2019-2020, le comité d’évaluation de l’HCERES estimait que « Lyon 3 n’est pas en mesure de suivre son activité de recherche de façon efficace, le système d’information GRAAL, dont dispose l’établissement, étant obsolescent et à remplacer ».
Pour combler cette lacune, la gouvernance se mobilise en inscrivant dans le projet d’établissement 2021-2026 le « développement d’une application agrégeant les données bibliographiques et bibliométriques des unités de recherche ».
Le résultat fructueux à un appel à projet lancé par le Rectorat dans le cadre du dialogue stratégique de gestion permet d’amorcer le développement du projet avec le recrutement d’un chargé de projet en novembre 2022 et l’attribution d’un marché concurrentiel à la société Dyoneo en mars 2023.
Un financement supplémentaire, obtenu fin 2024 dans le cadre de l’appel à projet « Programme de Coopération » initié par l’Abes, a permis de consolider l’assise du projet tout en élargissant la palette des sources bibliographiques de l’outil au Sudoc.
Au-delà du défi technique, l’enjeu consistait à construire une application adaptée à la réalité du paysage éditorial en sciences humaines et sociales, caractérisé par l’atomicité de ses éditeurs et le plurilinguisme de ses publications. Les grandes plateformes commerciales habituellement utilisées à des fins de bibliométrie ne couvrent en effet que très imparfaitement le périmètre des publications en SHS.
En amont, il nous semblait primordial de doter l’établissement d’un outil offrant un accès souverain et pérenne aux données bibliographiques collectées, qui remontent à 2014. En aval, il s’agissait de bénéficier d’une application pleinement administrable et de déterminer des indicateurs utiles à l’établissement, tout en exerçant une capacité de contrôle sur la fiabilité et la traçabilité des chiffres avancés.
Le référentiel auteurs et les identifiants uniques
Le périmètre actuel de BiblioRef correspond aux personnes affiliées à l’université ayant une activité de recherche donnant lieu à des publications, depuis 2014. Cela concerne la communauté des chercheurs au sens large (maîtres de conférences, professeurs des universités, doctorants, ATER, PRAG, PAST, émérites, etc.).
Chacun de ces profils dispose d’une fiche dans BiblioRef, comprenant des informations d’état civil (prénom, nom, date de naissance), d’autres liées au statut (structures et grades successifs, avec dates d’entrée et de sortie, section CNU, discipline, diplômes, etc.) et des identifiants auteurs.
Actuellement, BiblioRef gère six identifiants auteurs, qui ont pour la plupart été renseignés manuellement dans ces fiches. Plus précisément, quatre identifiants permettent la récupération des publications via les connecteurs : IdRef, IdHAL, ORCID[1], OpenAlex Author ID. Les deux autres identifiants auteurs servent à la gestion interne (matricule RH et numéro d’étudiant pour les doctorants non-financés).
Parmi l’ensemble des identifiants, l’IdRef représente l’outil pivot : il est non seulement le plus usité mais également celui que les bibliothécaires peuvent créer en cas d’absence des autres types d’identifiants. Un important travail d’alignement des IdRef a été réalisé au début de projet via un export RDF de la base auteurs de l’outil. Le référentiel ainsi constitué représente une base de données inédite au sein de l’Université, fruit d’un travail colossal d’agrégation et de nettoyage de données, avant la mise en place prochaine d’un processus plus automatisé, actuellement en cours d’instruction.
Quatre ans après le lancement du projet, BiblioRef est désormais pleinement opérationnel en utilisation de routine ou dans le cadre d’échéances ponctuelles importantes comme les campagnes d’évaluation HCERES, qui nécessitent un suivi fin des effectifs des laboratoires.
Une dizaine d’indicateurs statistiques sont par ailleurs fournis selon la granularité souhaitée (établissement, unité de recherche ou chercheur individuel), à partir de trois sources bibliographiques (HAL, Sudoc et OpenAlex) requêtées chaque semaine grâce aux identifiants chercheurs (IdRef, IdHal, ORCID, OpenAlex author ID[2]) pour import et dédoublonnage dans la base de données de BiblioRef.
L’import des données Sudoc
La récupération des données Sudoc avait pour but d’enrichir la base bibliographique de BiblioRef grâce aux ouvrages et thèses qui ne sont pas signalés dans HAL ou OpenAlex.
La récupération des données se fait en deux temps : des requêtes SPARQL permettent de récupérer les identifiants des notices Sudoc via data.idref, puis le connecteur Sudoc collecte les métadonnées correspondantes afin de constituer la notice bibliographique de la publication.
Pour le Sudoc, l’IdRef est l’identifiant unique qui permet de faire le lien avec le référentiel auteurs de BiblioRef et d’importer les références correspondant uniquement aux auteurs de l’établissement.
Afin d’assurer la mise en correspondance des métadonnées du Sudoc avec le modèle de données de BiblioRef, le chargé de projet et le développeur ont mené un travail d’alignement entre les champs de BiblioRef et les zones UNIMARC du Sudoc. Ils ont pu s’appuyer sur la documentation de l’Abes (notamment le Guide méthodologique du Sudoc) dans ce travail d’identification et de vérification des correspondances et ont bénéficié de la contribution d’un collègue de l’Abes, François Mistral, qui a apporté des conseils pour la partie relative à data.idref.
Des tests et réglages ont été nécessaires afin de calibrer au mieux la récupération des références correspondant au périmètre de l’établissement. Quatre types de références ont été ciblées : les ouvrages (monographies imprimées et électroniques), les thèses de doctorat (via les données theses.fr/STAR), les actes de colloques (imprimés et électroniques), les habilitations à diriger des recherches (HDR).
Le connecteur Sudoc permet à ce jour d’importer dans BiblioRef 2 006 références provenant uniquement de cette source, dont 1 017 ouvrages et 689 thèses.
Grâce aux données du Sudoc, BiblioRef se distingue désormais en tant qu’application bibliographique et bibliométrique spécialisée dans les SHS, avec une bien meilleure représentativité des monographies et des thèses.
BiblioRef dispose de deux grandes fonctionnalités de déboulonnage.
- Un premier dédoublonnage automatique est effectué au niveau des connecteurs et du Harvester, sur la base de critères stricts permettant de s’assurer qu’il s’agit de la même publication.
- Ensuite, un dédoublonnage manuel est possible dans un écran dédié, pour traiter les potentiels doublons identifiés comme tels, mais pour lesquels une vérification humaine est nécessaire (titre proche, date de publication différente).
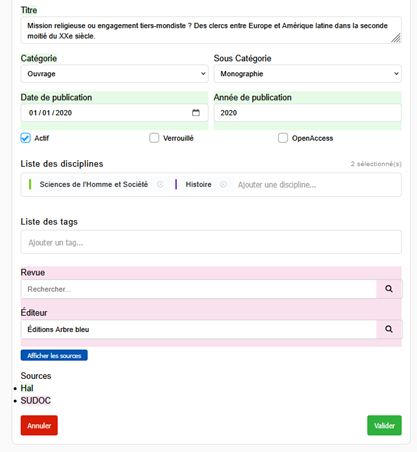
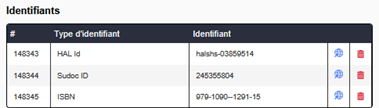
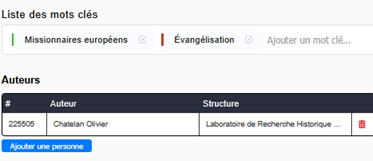
Ce double système de dédoublonnage permet d’enrichir les notices des références avec les métadonnées provenant de plusieurs sources, comme en témoigne l’exemple ci-après, où le Sudoc a permis d’enrichir les métadonnées en fournissant le nom de l’éditeur et les mots-clés.
Et après ?
La refonte d’envergure du système d’information de l’Abes, menée dans le cadre du projet ORION, aboutira au remplacement du Sudoc d’ici fin 2027. Les données importées d’ici cette échéance sont stockées dans la base de données de BiblioRef et resteront donc accessibles en local.
Au-delà de 2027, il sera nécessaire de rouvrir un chantier technique afin de construire un connecteur adapté aux nouveaux outils et services documentaires de l’Abes.
Marie-Emilia Herbet et Damien Petermann, SCD de l’université Lyon 3
[1] BiblioRef permet d’importer directement les ORCID depuis les notices IdRef grâce au webservice de l’Abes (idref2orcid).
[2] Pour HAL, BiblioRef utilise 3 identifiants auteurs : IdHAL, ORCID et IdRef, si celui-ci est présent dans la notice AuréHAL des personnes du référentiel auteurs. Pour OpenAlex, c’est l’OpenAlex Author ID qui est utilisé.