
Cet article est proposé par Géraldine Geoffroy (SCD Université Nice Sophia Antipolis) en tant que porteuse de l’application SudocToolkit, première contribution partagée via la toute récente communauté Github « abes-esr« . Qu’elle en soit ici vivement remerciée !
Lors d’une session parallèle des dernières Journées Abes (2019), l’équipe informatique de l’Abes a présenté son projet de co-construction d’applications, basé sur l’ouverture des codes sources et le respect des méthodes de l’open source pour le développement et la diffusion des applications, web services, prototypes etc… C’est un changement de braquet notable sur le chemin de la collaboration intra-réseau… et maintenant que l’Abes a fait le premier pas, c’est à nous, membres des réseaux – “bibliothécaires-systèmes” des BU (pour reprendre la terminologie de l’Abes) – d’emprunter le même chemin en partageant, autant que faire se peut, dans un espace commun les codes des applications que nous développons autour des données du Sudoc (et d’Idref, et de theses.fr…), dans et pour nos établissements respectifs.
![]() C’est chose faite pour le SCD de Nice avec la création d’une team azur-scd dans l’espace Github abes-esr, et le transfert d’une première application répondant au nom de SudocToolkit.
C’est chose faite pour le SCD de Nice avec la création d’une team azur-scd dans l’espace Github abes-esr, et le transfert d’une première application répondant au nom de SudocToolkit.
L’esprit de cette application…
… est de fournir, via l‘installation d’un utilitaire sur son PC, une interface utilisateur pour faciliter l’accès et l’usage des web services du Sudoc, notamment pour ceux qui ne sont pas « bibliothécaire-système » mais ont tout de même besoin d’obtenir de manière automatisée certaines données au-delà du niveau local, par exemple dans le cadre d’opérations de gestion de collection (ex : nombre de bibliothèques localisées dans le catalogue Sudoc, correspondance entre ISBN et ppn(s) …).
Techniquement (enfin, plutôt non techniquement justement !), le recours à une API de type REST, est relativement simple : il suffit de construire l’URL de sa requête en associant l’URL racine de l’API et les paramètres souhaités (en clair : il faut lire la documentation de l’API), puis d’envoyer sa requête par le protocole HTTP au serveur (en clair : taper l’URL dans la barre d’adresse de son navigateur).
Là où les choses se corsent, c’est au moment d’exploiter les données structurées – en général sérialisées en XML et/ou JSON – renvoyées par le serveur : on peut interroger manuellement une API avec quelques requêtes et examiner de visu les flux de résultats (voir par exemple cette requête issue de la documentation dans l’espace pro de l’Abes). Cependant, ces standards sont avant tout dédiés à l’échange de données entre machines, l’intervention humaine consistant éventuellement à écrire le programme intermédiaire qui explore, reformate, transforme ou enrichit les données.
L’accès (automatisé et en autonomie s’entend) à des données, pourtant ouvertes et distribuées par ce type de services, ne va donc pas forcément de soi pour la plupart des bibliothécaires. Pourtant, comme c’est le cas pour les données du Sudoc, celles-ci peuvent s’avérer indispensables aux opérations de gestion courante des collections – hélas non disponibles facilement, car non gérées par les SIGB (c’est le cas des localisations Sudoc par exemple).
Parmi les configurations concrètes possibles…
… citons par exemple le cas où la bibliothèque a besoin de connaître le taux de recouvrement de sa collection avec le Sudoc sur la base d’un listing d’ISBN (traitement de dons, rétro-conversion) ; de vérifier les ppn de sa base locale qui auraient été fusionnés depuis leur intégration (quand le SIGB ne gère pas les mises à jour de fusion) ; de disposer des RCR localisés dans le Sudoc lors d’opérations de désherbage…
SudocToolkit constitue une réponse possible (et modeste) à ce type de problématiques, même s’il en existe d’autres, plus complètes, qui répondent à la même logique d’intermédiation entre flux de données structurées et utilisateur “lambda” (voir par exemple la plateforme EzLibrAPI réalisée, et présentée lors de cette même session parallèle, décidément très instructive, par les collègues lillois de la BU Vauban de l’université Catholique de Lille).
Installation et utilisation
SudocToolkit se présente comme une application de bureau, développée en Javascript avec le framework Electron, installable sous Windows avec un exécutable accessible en téléchargement ici : https://github.com/abes-esr/SudocToolkit/releases (choisir la version la plus récente).
Après avoir téléchargé et dézippé l’archive n’importe où sur votre poste, il suffit de double-cliquer sur SudocToolkit.exe pour lancer l’application. Vous pouvez également créer un raccourci depuis votre bureau par un clic droit sur SudocToolkit.exe puis « Envoyer vers -> Bureau » (et renommer le dossier dézippé).
L’utilisation de l’application est censée être simple (sinon ça signifie que c’est raté !) et logique : on part de l’import d’un fichier au format .csv comportant a minima une colonne d’identifiants sources (ppn, ISBN ou ISSN) et on aboutit à la fourniture en sortie d’un fichier de résultats (au format csv) comportant une colonne supplémentaire générée avec les données récupérées grâce à l’API utilisée.
A noter quelques fonctionnalités additionnelles :
- après avoir importé un fichier de départ, l’application analyse les différentes colonnes : il est alors possible de sélectionner la colonne des identifiants sur lesquels on souhaite faire tourner le web service choisi, puis les colonnes qu’on souhaite conserver dans le fichier produit en sortie.

- permet de suivre en temps réel la progression des appels successifs au web service

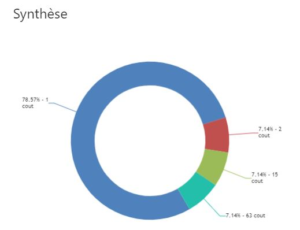
- propose une visualisation synthétique consolidée de la répartition des résultats
Pour l’instant (mais ce n’est qu’un début !), 4 API sont interrogeables via le SudocToolkit. Elles permettent de réaliser les opérations suivantes :
- « isbn2ppn : compter le nombre de ppn renvoyés par isbn » : permet, sur la base d’ISBN (10 ou 13, tirets acceptés), de compter le nombre de ppn renvoyés par le web service isbn2ppn
- « isbn2ppn : obtenir les ppn uniques par isbn » : utilisé dans le cas où, via l’opération précédente, on sait déjà qu’un ppn unique correspond à chaque ISBN, ce web service permet, sur la base d’ISBN, d’obtenir la valeur de chaque ppn
- « issn2ppn : obtenir les ppn uniques par issn »: idem, sur la base d’ISSN (avec ou sans tirets) ;
- « merged : obtenir les ppn préférés en cas de fusion »: sur la base de ppn, obtenir le ppn actif si fusion par le web service merged ;
- « multiwhere : compter les localisations par ppn » : sur la base de ppn, compter le nombre de RCR localisés et renvoyés par le web service multiwhere.
C’est une première version, cette application est possiblement amenée à s’enrichir avec d’autres web services ou des fonctionnalités supplémentaires, notamment en fonction des besoins exprimés. Et justement, pour vous exprimer, vous pouvez :
- écrire à GEOFFROY@univ-cotedazur.fr…
- poster une « issue » sur le Github : https://github.com/abes-esr/SudocToolkit/issues, c’est fait pour ça !
Géraldine Geoffroy, SCD-BU Université Nice Sophia Antipolis, Département Sidoc, chargée d’ingénierie documentaire
- Accéder au SudocToolkit : https://github.com/abes-esr/SudocToolkit
- Télécharger le SudocToolkit : https://github.com/abes-esr/SudocToolkit/releases
Ping : Le GitHub de l'Abes : un lieu de partage et d'ouverture - FIL'ABES