
[English abstract at the bottom of this blog’s post]D’un point de vue technique, charger des corpus de livres dans le Sudoc n’est pas très difficile. Depuis plusieurs années, les équipes de l’Abes importent régulièrement des ensembles de notices MARC en provenance de différents éditeurs (Springer, CAIRN …) et, globalement, ces notices sont bien utilisées par les bibliothèques du réseau.
Pourquoi un nouveau workflow d’imports de données dans le Sudoc ?
Pour autant, on a pu constater que ce système comporte des limites : en amont, il n’est pas toujours évident de récupérer auprès des éditeurs des notices MARC – si possible de bonne qualité, cette démarche exigeant généralement de nombreux aller-retours. En aval, ce type d’opérations de chargement dans le Sudoc requiert des interventions et compétences spécifiques, relativement rares à l’Abes. Autant d’éléments qui rendent les processus actuels difficilement scalables et difficile aussi l’atteinte de l’objectif de signalement total. Aussi, il s’est avéré indispensable de réfléchir à la conception de nouveaux workflows, afin de réaliser automatiquement les opérations d’ingestion, transformation, enrichissements et chargement dans le Sudoc.
Sélection du corpus test
La conduite de l’expérimentation nécessitait un corpus répondant à quelques critères simples :
-
- les métadonnées devaient être accessibles (FTP, API…) pour que le workflow puisse être automatisé
- les métadonnées devaient être accessibles (FTP, API…) pour que le workflow puisse être automatisé
-
- les métadonnées devaient être dans un format standard – mais pas nécessairement au format MARC
-
- le chargement du corpus devait répondre à un besoin du réseau, constaté mais non encore satisfait
- ce corpus devait correspondre à l’ensemble du catalogue d’un éditeur ou à un sous-ensemble identifiable, quelque soit le support (imprimé / numérique)
Une analyse menée en 2016 avait permis l’identification de la liste des éditeurs représentant la plus forte activité de catalogage dans le Sudoc. Le choix s’est rapidement porté sur Oxford University Press (OUP), second de cette liste avec 1757 titres de monographies imprimées catalogués en 2016 et répartis sur 131 ILN.
 Avec une production annuelle d’environ 4400 titres, OUP met la version électronique de ses ouvrages à disposition via sa propre plate-forme et via des agrégateurs (Proquest, Dawson, OAPEN…). Autre intérêt spécifique : sur le site http://databank.oup.com/gb, les métadonnées des ouvrages du catalogue imprimé OU sont disponibles au format ONIX 2.1 ainsi que les fichiers KBART décrivant les bouquets de monographies électroniques (voir ici).
Avec une production annuelle d’environ 4400 titres, OUP met la version électronique de ses ouvrages à disposition via sa propre plate-forme et via des agrégateurs (Proquest, Dawson, OAPEN…). Autre intérêt spécifique : sur le site http://databank.oup.com/gb, les métadonnées des ouvrages du catalogue imprimé OU sont disponibles au format ONIX 2.1 ainsi que les fichiers KBART décrivant les bouquets de monographies électroniques (voir ici).
Les éléments étaient donc en place pour lancer l’expérimentation, l’objectif étant de mettre à disposition, sur un rythme hebdomadaire, les notices des ouvrages imprimés et électroniques du catalogue OUP dans la base de production Sudo.
Un nouveau workflow
Première étape : Ingestion
Après un simple enregistrement, le site http://databank.oup.com propose l’export de données du catalogue OUP, dans son intégralité ou par sous-ensembles éditoriaux, au format ONIX 2.1 et/ou tabulé. Nous avons fait le choix de récupérer le flux ONIX exposant hebdomadairement toutes les nouvelles publications d’OUP. Par défaut, l’éditeur propose d’envoyer les données par FTP. Pour des raisons de sécurité, nous avons préféré les récupérer directement sur son FTP, ce que l’éditeur a accepté. Pour ce faire, un simple script shell se lançant à intervalles réguliers se connecte au serveur FTP d’OUP, prend le dernier fichier en date et le copie localement.
Deuxième étape : Transformation et enrichissements
Cette étape constitue l’enchaînement de plusieurs procédures s’exécutant dans des environnements différents : transformations XSL ; requêtes SQL et procédures dans le système de gestion de base de données ORACLE ; requêtes SPARQL dans une base RDF Virtuoso ; programmes externes d’alignements… Le tout piloté par une interface graphique de gestion de workflow qui, grâce à l’agencement des différentes briques entre elles, offre une bonne visibilité sur l’étape où d’éventuels problèmes peuvent se présenter (un peu comme Yahoo pipes, pour ceux qui s’en souviennent).

Un aperçu de l’interface graphique de gestion de workflows
Dans un premier temps, les données fournies par l’éditeur sont converties en RDF. Pour se remémorer les raisons du choix de ce format pivot, on pourra avantageusement se replonger dans ce document.
Une grosse partie du travail de préparation consiste à analyser les données afin de comprendre comment l’éditeur utilise ONIX 2.1, en pariant que l’éditeur reste cohérent dans le temps avec ses propres choix afin que le mapping – entre ONIX et les propriétés sélectionnées dans différents vocabulaires – n’évolue qu’à la marge, voire pas du tout. Une fois le mapping validé et le chargement en base RDF réalisé, les étapes d’enrichissements peuvent commencer.
Il peut s’agir d’appeler de simples webservices, comme par exemple le webservice “classify” d’OCLC qui, à partir d’une interrogation ISBN dans Worldcat, renvoie l’indice Dewey. Cela peut nécessiter des opérations plus complexes : toujours à partir de l’ISBN, on récupère en parsant le Html grâce à une librairie Java tous les triplets auteurs affichés dans Worldcat via l’encart “données liées” (cf schéma ci-dessous), et on obtient les identifiants VIAF associés.
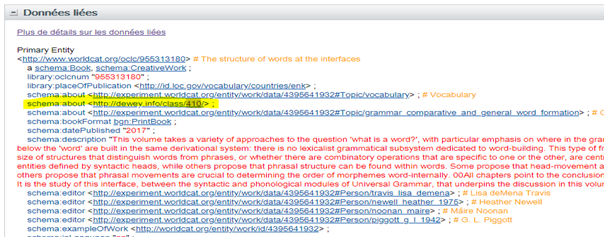
Exemple de données liées pour l’ISBN 978-0-19-877827-1 :
http://www.worldcat.org/title/structure-of-words-at-the-interfaces/oclc/955313180&referer=brief_results
A l’aide d’une fonction développée précédemment par le LIRMM dans le cadre du projet Qualinca, on peut également comparer, pour un ISBN donné, les noms OUP avec les noms Worldcat correspondants. Si la comparaison est satisfaisante, on intègre l’identifiant VIAF dans le graphe, et, de là, on obtient l’identifiant IdReF en interrogeant le dump mensuel de VIAF via une requête SPARQL.
Ensuite, l’algorithme d’alignement avec IdRef – également développé dans le cadre du projet Qualinca – est lancé sur l’ensemble du corpus ce qui permet : de récupérer dans le graphe des identifiants que l’on n’aurait pas obtenus avec la méthode précédente mais également de confirmer les résultats, ou au contraire, de mettre en évidence des incohérences qui sont alors identifiées et traitées.
On dispose ainsi de presque toutes les informations pour faire de « belles notices » Sudoc. Presque … car il manque encore l’information permettant de générer les zones 452$0 (« Autre édition sur un autre support »), ce qui est tout à fait logique : pour traiter les ouvrages électroniques, il faut auparavant finaliser les étapes du workflow “imprimé” pour lancer le workflow “électronique”. Pour ce faire, il reste à exporter les données RDF dans une table Oracle dédiée, effectuer une série de conversions (de RDF en MARCXML puis de MARCXML en MARC ISO2709) via des procédures Java, et les données sont prêtes pour le chargement.
Troisième étape : chargement
Cette étape a longtemps été manuelle, car des réglages et ajustements effectués au niveau des tables de paramétrages de CBS dépend la qualité globale du Sudoc. C’est en particulier à ce moment que l’on fixe les règles pour définir ce qu’il advient des doublons avérés et suspectés. Pour autant, l’objectif étant de tout automatiser, il a fallu convenir de la meilleure méthode d’identification et de traitement des candidats-doublons sans intervention humaine.
C’est désormais chose faite : notices uniques et candidats-doublons sont versés automatiquement en base de production et récupèrent un PPN. Bien évidemment, tout le processus est encore scruté de près afin de s’assurer que ces opérations maintiennent un bon niveau de qualité de la base. Les triplets comprenant les PPN sont alors injectés dans la base RDF.
Et les notices de ressources électroniques ?
Jusqu’à présent, on ne s’est intéressé qu’aux ouvrages décrit via le flux ONIX d’OUP. Ce service comporte hélas un défaut majeur : il ne traite que les métadonnées de documents imprimés. Impossible à partir de ces données de reconstituer des notices de documents électroniques : il manque en effet des éléments essentiels, comme l’ISBN électronique ou l’URL d’accès.
Heureusement, ces informations sont disponibles via un autre canal : les fichiers KBART d’OUP. Un autre workflow a donc été créé pour traiter ces données : tout d’abord, les fichiers sont récupérés par la base de connaissance BACON suivant les procédures habituelles, un programme scannant les fichiers à la recherche d’éventuelles mises à jour. Pour faciliter la suite des opérations, un fichier agrégeant toutes les monographies est constitué à chaque changement. Les données de BACON pertinentes sont ensuite chargées dans un graphe particulier de la base RDF.
L’ISBN de la version imprimée – présent dans les données BACON – sert de pivot pour raccrocher les données de la manifestation électronique (ISBN électronique, date de publication, URL) aux données d’œuvre, exprimées dans celles de la manifestation imprimée (titre, auteurs, indexation…), ce qui fait le lien entre les manifestations. Ainsi, la fameuse zone 452$0 peut être remplie puisqu’à ce moment du processus, on dispose du PPN de la version imprimée.
Mécanisme pour obtenir une notice « électronique » à partir d’une notice « imprimé » et d’un fichier KBART
Pour finaliser le processus, la conversion au format MARC et le chargement dans le Sudoc suivent les étapes décrites précédemment. Nos notices électroniques disposent alors chacune d’un PPN, injecté dans la zone 452$0 des notices imprimées via le programme MarcEdMod, outil interne de modification des données Sudoc. Ces données remontent à leur tour dans la base de graphes via la base XML, synchronisée avec le CBS.
La boucle est bouclée : à partir d’informations bibliographiques provenant de sources diverses, nous obtenons des données en RDF et des notices MARC utilisables par le réseau.
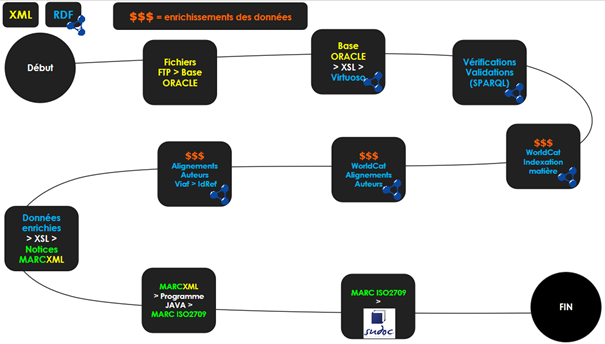
Le workflow d’import utilisé pour OUP
Conclusion
Cette expérimentation, qui met en œuvre une gamme d’outils, processus et concepts développés depuis plusieurs années par l’Abes, démontre qu’il est possible de s’affranchir du format MARC en entrée, pour peu que les métadonnées mises à disposition par l’éditeur soient suffisamment structurées. Si l’heure n’est pas encore au bilan – puisque la peinture sèche à peine, on peut déjà exprimer quelques remarques et aspirations pour l’avenir.
La première remarque offre des perspectives intéressantes : la grande modularité de l’outil de gestion de workflow permet d’envisager autant d’enrichissements que souhaité, pour peu que l’on ait la matière et les outils pour le faire. On pourrait par exemple imaginer inclure dans le workflow un outil d’indexation automatique s’appuyant sur l’analyse des résumés ou des tables des matières.
L’ensemble du processus comporte néanmoins quelques limites. Les notices de la base Sudoc ont vocation à y vivre, à être utilisées, enrichies. Partant du principe que les modifications apportées par les professionnels du réseau sont supérieures en termes de qualité à celles produites automatiquement, le choix a été fait de ne pas mettre à jour via les workflows décrits, les notices intégrées lors d’un import antérieur, ce, qui aurait exigé de réfléchir à de complexes règles de fusion d’informations. Inversement, du fait qu’il n’y a pas – pour l’heure – de synchronisation entre le Sudoc et la base RDF de travail, les données n’évolueront malheureusement que dans le Sudoc.
Enfin, même s’il s’affranchit du format MARC, ce workflow suppose que les éditeurs ou agrégateurs aient la volonté d’ouvrir leurs métadonnées, celles-ci étant largement utilisées et diffusées dans les silos que sont les bases des sites de vente en ligne – car c’est bien à cela que sert ONIX ! – ou les outils de découvertes pour bibliothèques. Plusieurs gros éditeurs ont déjà fait ce pari d’ouverture, ce qui va permettre à quelques corpus d’ores et déjà de rejoindre le corpus OUP dans le Sudoc. Il reste à espérer que les initiatives comme Metadata2020 rendront cela encore plus courant !!!
English abstract
Here is a short abstract of this post so it can be more easily discovered and understood by non French speakers.
The French Bibliographical Agency for Higher Education(ABES) has build a workflow to automatically feed its shared cataloguing system / union catalogue with records of printed and electronic content based on several sources. The corpus used to lead this experimentation are the books published by Oxford University Press, a major publisher for our network (in 2016, OUP was the 2nd biggest publisher regarding the number of new records manually created in the SUDOC with 1757 records).
OUP’s ONIX feed is downloaded weekly via FTP. The transformation and enrichment processed is then entirely conducted and monitored thanks to a workflow GUI which can combine calls to XSL transformations, ORACLE queries and stored procedures, SPARQL queries in Virtuoso, and reconciling services. The more time consuming step is the mapping from ONIX to RDF, thanks to several vocabularies. Once the data are converted into RDF, all the enrichments can be made, either thanks to basic webservices (eg OCLC Classify) or thanks to elaborate reconciling services built by ABES and its partner (LIRMM) which can get identifiers for authors from IdRef, the SUDOC authority file. This workflow produces metadata only for print content. OUP ONIX feed does not contain metadata for electronic content which have to be sourced from the KBART files OUP provides. KBART files are first ingested by the French open knowledge base BACON ; the information is then converted into RDF and stored in the Virtuoso database. The print ISBN which can be found both in the ONIX feed and the KBART files is the pivot that links and merges data from the electronic manifestation (online ISBN, URL, online publication date)) to the data of the work expressed in the print manifestation (title, authors, subject headings) and one manifestation to another.
Data are then converted back from RDF to MARCXML then to MARC ISO2709 (UNIMARC) with Java procedures and loaded into SUDOC main production database (CBS).
Ping : Nouveau Workflow d’import automatisé dans le Sudoc : première évaluation - PUNKTOKOMO
Ping : Chantier BACON – partie 1: liage du Sudoc et de BACON par les PPN - PUNKTOKOMO
Ping : Nouveau workflow d’import automatisé dans le Sudoc : les ouvrages publiés par Cambridge University Press - PUNKTOKOMO