
Ce démonstrateur est un plaidoyer en faveur d’une approche “web sémantique” de l’interopérabilité des données de l’IST. Mais, cette fois, il s’agit de montrer et non d’argumenter. Il s’agit de défendre, en illustrant cette approche par des études de cas. Alors, si vous fuyez les plaidoyers, si vous exigez du concret, de la donnée (RDF), de la requête (SPARQL), passez cette introduction et lisez l’un des billets suivants :
- Introduction (ce billet)
- Inventaire des données
- Suivez le guide ! Le modèle de données
- Études de cas
- Nature en VOSTFR
- Les revues d’Oxford UP et la classification JEL (économie)
- Les ebooks Springer, IdRef, RAMEAU, Dewey
- Le même auteur dans IdRef, VIAF, HAL, Persée, etc.
- Mapping entre structures de recherche de Paris 4 : IdRef/RNSR/HAL
- Matrice des fascicules pour conservation partagée
- Le bouquet des ebooks Dalloz
- La fédération a de l’avenir
SPARQL endpoint : https://lod.abes.fr/sparql
Interface de recherche full text et de navigation : https://lod.abes.fr/fct
Pourquoi ce démonstrateur
Mettre nos données en réseau, c’est structurer et publier nos données conformément aux principes et aux bonnes pratiques du web sémantique.
Nos données, ce sont à la fois les données produites par les réseaux ABES (Sudoc, Sudoc PS, Thèses, Calames) mais également toutes ces données voisines, complémentaires produites par les éditeurs, l’administration, les institutions culturelles, les institutions dédiées à l’information scientifique et technique (IST).
Ce périmètre est par définition extensible : par exemple, si nos données, ce sont d’abord les métadonnées de thèse électronique produites ou importées dans STAR, ce sont également les informations sur l’équipe de recherche (RNSR, HAL, IdRef), l’école doctorale (Ministère, IdRef), l’entreprise qui finance le contrat CIFRE (ANRT), les articles du doctorant (HAL et autres archives, éditeurs), la production du directeur de thèse (HAL, éditeurs), les vocabulaires contrôlés qui décrivent le contenu (RAMEAU, MeSH, tel vocabulaire spécialisé, etc.), les bibliothèques qui possèdent telle thèse, etc.
Second exemple : nos données, ce sont d’abord les métadonnées des articles acquis dans le cadre d’ISTEX (ISSN, Sudoc), mais ce sont également les métadonnées des revues, des fascicules et des volumes, les métadonnées des auteurs (IdRef, ISNI, VIAF, ORCID, HAL, Persée, Wikipedia, etc.), les affiliations, les vocabulaires contrôlés, les métadonnées sur le package commercial correspondant à l’acquisition (BACON, GoKB), la licence, les bibliothèques couvertes par la licence, etc.
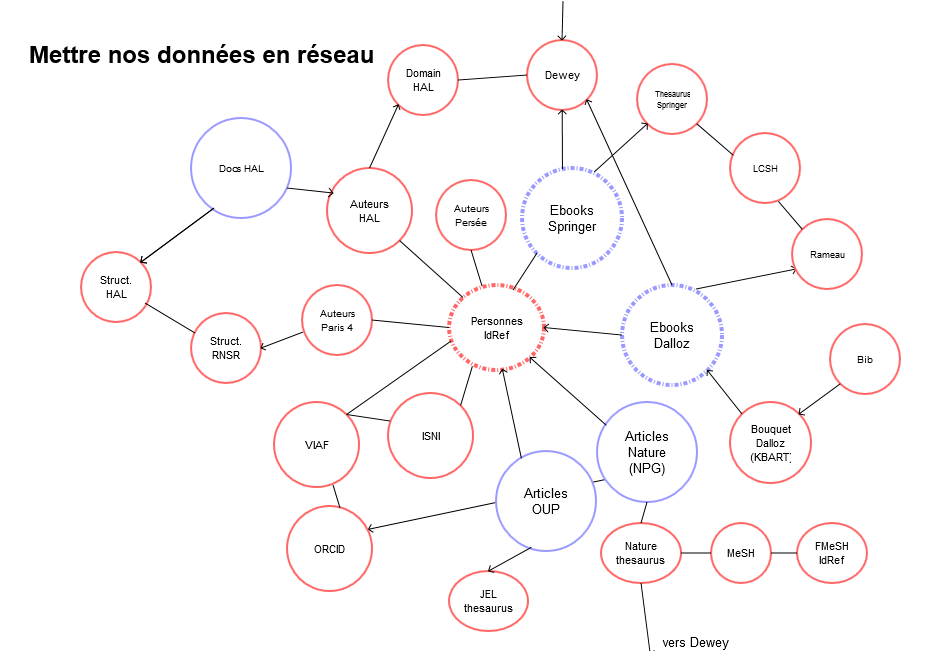
Troisième et dernier exemple : pour savoir que tel auteur est affilié à l’université Paris 4, on a besoin de remonter le courant : de telle notice Sudoc à tel auteur IdRef, puis à tel auteur HAL, puis à tel document HAL, puis à telle équipe de recherche du référentiel HAL, puis à cette même équipe dans le référentiel RNSR, équipe rattachée à Paris 4. Il existe un chemin plus court, mais dans tous les cas, il faut être agile, rebondir d’une base à l’autre, d’un organisme à l’autre.
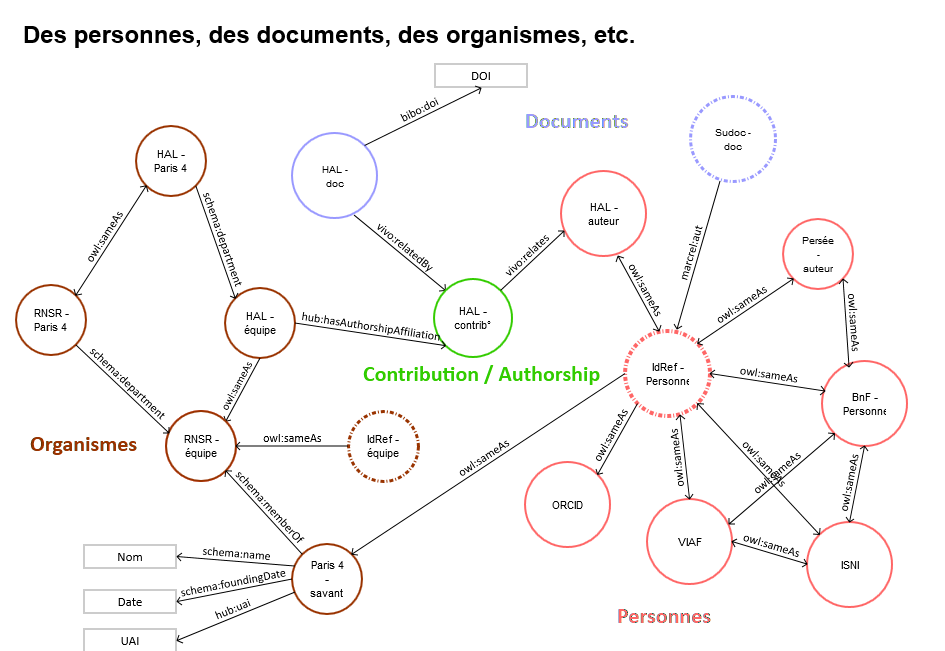
L’information est par définition extensible. On ne peut définir a priori le périmètre des données qui correspond à nos besoins. La gestion de l’information doit être aussi extensible que l’information elle-même.
Et précisément, les technologies du web sémantique sont faites pour ça : établir des liens effectifs entre données complémentaires, sans fixer à l’avance ni le périmètre des données, ni la nature de ces liens.
Une base RDF + des requêtes SPARQL
Ce démonstrateur n’est rien d’autre que l’agrégation de données RDF brutes au sein d’une seule base de données. Si ce n’est préparer et documenter ces données, nous n’avons rien fait d’autre : ni construction d’index pour interroger les données, ni développement d’un web service de recherche, ni réalisation d’une interface graphique. Nous nous sommes contentés de charger ces données brutes dans une base RDF supportant le langage de requête SPARQL : ipso facto, nos données sont devenues interrogeables, consultables, navigables.
Pour interroger nos données, il suffit de se rendre à cette adresse : https://lod.abes.fr/sparql et de lancer une requête SPARQL. SPARQL est un langage très puissant, qui demande un apprentissage progressif. Mais tous les billets de cette série proposent des exemples de requête. Ce sont de bons points de départ. Si vous vous prenez au jeu, forgez vos propres requêtes et les jugez intéressantes, merci de les partager en commentaires.
SPARQL est un langage mais également un protocole web , c’est-à-dire un web service : https://lod.abes.fr/sparql n’est donc pas seulement une page web pour fans des données, mais également l’URL principale d’un web service de recherche qui permet à n’importe quel programme d’interroger une base RDF et d’en exploiter les résultats sous différents formats (HTML, XML, CSV, JSON, etc.). Grâce à SPARQL, nous pourrons offrir une API standard pour interroger de manière sophistiquée les corpus ISTEX, par exemple, en complément de l’API de recherche développée par l’INIST. On a besoin des deux : une base de données ouverte et un moteur de recherche ouvert.
Si vous n’êtes ni un geek ni un programme, vous avez la possibilité de vous promener dans les données de notre base via cette interface, livrée avec le logiciel qui gère notre base de données : https://lod.abes.fr/fct. Chaque page de cette interface correspond à une entité de notre base (un article, une personne, un concept, etc.). Ainsi, la page https://lod.abes.fr/describe/?url=http://hub.abes.fr/springerB/ebook/3540183000/w décrit l’ebook identifié par : http://hub.abes.fr/springerB/ebook/3540183000/w. (Si vous activez cette URL, conformément aux principes des linked data (par TBL, il y a dix ans), vous serez redirigé vers une page qui décrit ce document : ne pas confondre la chose et sa description).
Cet ebook est caractérisé par des attributs (son titre, sa langue) et par des relations : relations vers les concepts dont parlent ce livre, relations vers l’éditeur, relations vers les auteurs (via le concept de contribution), etc. Ce sont ces relations qui permettent de naviguer d’entité en entité, comme on parcourt une encyclopédie. On croit naviguer d’une page à l’autre, mais en fait on navigue aussi d’une chose à l’autre : d’un laboratoire vers une personne, d’une personne vers un document, d’un document vers un concept, etc. De proche en proche, l’ensemble de ces relations constitue un réseau de données, un web de données.
Stratégie du coucou ? Pourquoi mettre tous ces données dans le même panier ?
Il sera naturel de soulever l’objection suivante : vous n’allez pas prétendre enfermer le web de données dans le monde clos de votre base ? Par définition, le web est décentralisé et il doit en être de même pour le web de données.
Cette objection est tout à fait légitime : il y a quelque chose d’artificiel à vouloir démontrer l’efficacité du web sémantique comme solution d’interopérabilité en rassemblant au sein d’une même base tous les jeux de données qu’on veut interconnecter et faire interagir. Nous justifions ainsi notre choix :
La plupart des données que nous voulions entrelacer n’existent pas (encore) sous forme RDF. On s’y est collé, à des fins pédagogiques.
Les solutions pour interroger un web de données décentralisé ne sont pas encore tout à fait mûres. SPARQL prévoit bien la recherche fédérée mais, quel que soit le type de technologies, ce type de recherche achoppe toujours sur les mêmes difficultés (disponibilités des bases à interroger, performances).
Il va de soi que ce n’est pas à l’ABES de produire, maintenir et publier en RDF les données du RNSR, de HAL, de Paris 4 ou d’ORCID, voire de Nature ou Springer (d’ailleurs, la plupart de ces initiatives sont précisément en train de construire leur offre de service RDF – disons, à notre connaissance, 4 sur 6 – nous vous laissons deviner). Ce qu’on espère c’est précisément un monde où les uns et les autres, sans concertation, sans négociation, sans plan quinquennal, font le pari du web sémantique et, comme par miracle, contribuent à construire un espace public de données, souvent complémentaires, parfois redondantes, parfois dissonantes.
Il ne s’agit pas de s’accorder entre nous (même si ça aide et fait plaisir), mais de s’accorder sur les mêmes bonnes pratiques internationales, sur l’état de l’art.
Affirmons à nouveau que chaque producteur est responsable de publier ses données et que le consommateur a le choix des moyens pour les exploiter : requête SPARQL fédérée, navigation à travers des browsers sémantiques, récupération de données en local (ne serait-ce que pour leur faire jouer le rôle d’un cache). Chaque solution a ses avantages et ses contextes d’utilisation privilégiés.
Caveat emptor
- Ce démonstrateur est un démonstrateur.
- Ce démonstrateur est vivant et donc périssable. Nous nous réservons le droit d’y ajouter des données, d’en retirer et même de le passer par pertes et profits.
- Les URLs de ressources commençant par http://hub.abes.fr n’ont pas de durée de vie garantie. Encore moins les URLS pour les ressources de BACON, HAL, de Persée ou du RNSR.
- Certains jeux de données de la base sont complets (ORCID, Nature), d’autres ne sont que des échantillons (Annuaire Paris 4, Sudoc, IdRef, Oxford UP).
- L’approche web sémantique n’est pas l’alpha et l’oméga de l’interopérabilité. A côté de la puissance de SPARQL, coûteuse et pas toujours performante, il y a de la place pour des API hyperspécialisées et hyperoptimisées, comme les micro web services du Sudoc ou d’IdRef.
Ping : French academic libraries: ready (soon) for Open data & interoperability. | Open Linked Education Community Group