
Entre mai et novembre 2024, une série de billets ont été publiés conjointement sur les blogs de ROR et de Crossref par Adam Buttrick et Dominika Tkaczyk (Si vous avez un doute sur ce qu’est le ROR, pour Research Organizations Registry, allez réviser sur ce précédent billet Punktokomo.) Ils traitent d’un enjeu qui est à la fois central et quotidien pour le service Autorités et Référentiels de l’Abes : l’alignement. En anglais, on parle de matching.
Voyons comment ces collègues qui travaillent eux aussi toute la journée sur des métadonnées situent les choses, quel vocabulaire elles et ils emploient, vers quoi tendre et sur quels os on peut tomber.
Billets originaux : Metadata Matching , what is it and why do we need it ? et The Anatomy of Metadata matching
Qu’est-ce que sont les alignements ?

par Johanneke Kroesbergen-Kamps
L’alignement, pour des métadonnées, a pour objectif de rapprocher des sources pour apparier des entités (dans les cas qui nous occupent à l’Abes, des personnes physiques et/ou des organisations) qui sont considérées comme identiques.
On se lance dans des travaux d’alignement quand on sait, ou du moins qu’on suspecte, que deux sources de données parlent des mêmes choses. Par exemple, quand on entreprend d’aligner un annuaire des personnels d’une université vers IdRef, on suppose que les chercheuses, enseignantes-chercheuses, ingénieures[1] de recherche, etc. qui travaillent dans cette université ont probablement déjà une notice descriptive dans IdRef, car elles ont des rôles bibliographiques dans des documents signalés dans les gisements documentaires associés, comme le Sudoc et les thèses. Tout alignement commence donc par le présupposé d’un recouvrement.
Par ailleurs, pour ne pas mélanger les torchons et les serviettes, on ne se lance dans un alignement qu’en supposant aussi que la définition des entités qu’on veut apparier est suffisamment proche. Quand il s’agit de personnes physiques, c’est assez simple : chaque être humain est unique, et ne naît et ne meurt qu’une fois. La définition de base est la même. Une personne pourrait être décrite par plusieurs notices IdRef ou par plusieurs entrées dans un annuaire, mais alors, c’est un doublon : parce qu’on suppose l’unicité de chaque entité et un accord sur la définition de l’identité. Pour les collectivités, vous vous en doutez, c’est toujours un peu plus tordu, mais on y reviendra.
Pourquoi aligner ?
Voici la définition donnée dans le premier billet : “Matching in general can be defined as the task or process of finding an identifier for an item based on its structured or unstructured description.“ En français, on pourrait dire qu’il s’agit de l’appariement d’un élément décrit de manière plus ou moins structure avec un identifiant au sein d’un référentiel-cible.
Les alignements sont un chemin qui mèneraient au Graal (des bibliothécaires, et surtout des bibliomètres) qu’est la description complète du research nexus, c’est-à-dire du graphe de la recherche, qui décrit toutes les relations existantes entre les personnes, les organisations, les publications, les données, les financements, les projets, etc. Ces relations permettent d’inscrire toutes les entités dans un contexte, une constellation de points qui sont ancrés par des identifiants pérennes : ces PIDs garantissent l’unicité et l’identité. Et rendre ces entités et leurs relations explicites permet d’exploiter les données, pour les transformer en informations, voire en connaissance.
Comment s’y prendre ?
On peut aligner avec ses petites mains et ses petits moyens. C’est une méthode très très fiable, mais très très lente. Si l’on est pressé (ou plutôt qu’on applique de manière avisée les conseils de Paul Lafargue pour revendiquer notre droit à la paresse[2]), on peut utiliser des procédés automatisés. Ces procédés peuvent être soit supervisés, c’est-à-dire que la machine propose pour que l’humain dispose, soit entièrement délégués, quand aucune intervention humaine ne valide les conclusions automatiques. Mais avant de savoir quelle artillerie on mobilise, un petit point sur le vocabulaire.
Il s’agit d’abord de spécifier le projet d’alignement (matching task) et ce n’est pas si anodin qu’il y parait. A partir de quelques questions apparemment simples :
- Quel problème cherche-t-on à résoudre ?
- Quelles sont les données d’entrée (input) : leur format, leur structuration ou absence de structuration, les informations qu’elles contiennent, l’hétérogénéité possible ?
- Qu’attend-on comme résultat (ouput) : quels sont les identifiants cibles ? Attend-on un ou plusieurs identifiants, selon quelles conditions ? Veut-on que le résultat proposé soit assorti d’un indice de confiance, comme à la météo ?
On va choisir la ou les stratégies d’alignement ou heuristiques (matching strategies) mises en œuvre.
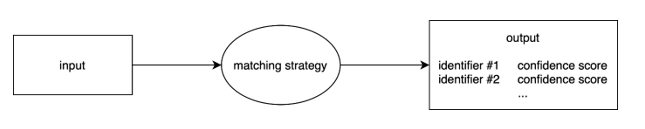
Ceci nous amène à considérer les questions suivantes :
Est-ce qu’aligner une chaîne de caractères (telle que peut apparaître une affiliation au sein d’une publication) et des métadonnées structurées vers un identifiant, c’est la même matching task avec deux sortes d’input, ou bien deux tâches complètement différentes ?
Où commence la matching task : avec l’ensemble du texte brut, ou bien seulement une fois qu’à l’intérieur, on a délimité des entités, à l’aide d’outils qui font de la Reconnaissance d’Entités Nommées (Named Entity Recognition – NER) ?
Ce que fait l’Abes
Au service Autorités et Référentiels de l’Abes, nous pratiquons deux familles d’alignements.
La première, qui correspond bien à ce qui est décrit dans les billets ROR et CrossRef, consiste à travailler notamment avec comme données d’entrée une extraction de l’annuaire des personnes d’un établissement, sous forme tabulée[3]. Ce sont donc des données structurées, à peu près homogènes, sur lesquelles on applique une stratégie standardisée (algorithme développé en interne), et pour lesquelles on attend comme résultat idéalement 1 IdRef par entrée proposée.
La seconde consiste à partir d’un identifiant, pour aller vers un autre. Les stratégies mises en œuvre sont plus diverses :
- Il peut s’agir d’une triangulation : si IdRef connaît pour une personne son ID Scopus, et que le même ID Scopus figure dans un profil ORCID, alors on peut postuler l’alignement entre l’IdRef et l’ORCID. Idem si un identifiant de structure dans AuréHAL connait un IdRef et que ce même identifiant AuréHAL est associé à un RNSR.
- Il peut s’agir d’une « pêche au filet » : à partir d’un identifiant (IdRef ou RNSR), on va chercher des publications qui possèdent cet identifiant dans les métadonnées d’affiliation, et on observe si des identifiants appartenant à d’autres référentiels sont présents également.
Rendez-vous dans le billet suivant pour démolir, toujours en suivant les billets co-publiés par ROR et CrossRef, les mythes relatifs à l’alignement.
Carole Melzac
Service Autorités et Référentiels
Abes
[1] La féminisation aléatoire des pluriels est une manière de pratiquer une écriture inclusive, qui permet de ne pas alourdir sa lecture tout en rappelant aux personnes qui lisent que dans un groupe, on trouve souvent plusieurs genres.
[2] « Le travail ne deviendra un condiment de plaisir de la paresse, un exercice bienfaisant à l’organisme humain, une passion utile à l’organisme social que lorsqu’il sera sagement réglementé et limité à un maximum de trois heures par jour » Le droit à la paresse, Paul Lafargue, 1880.
[3] C’est l’occasion de vous remémorer cette excellente infographie parue dans le numéro 112 d’Arabesques : https://publications-prairial.fr/arabesques/index.php?id=3845
Ping : Anatomie (pathologique) des alignements, épisode 2/3 - PUNKTOKOMO
Ping : Anatomie des alignements à l'Abes (ou métaphore des chaussettes), épisode 3/3 - PUNKTOKOMO