
En novembre 2022, un incident technique sérieux sur l’infrastructure du SI de l’Abes pénalisait les bibliothèques, les obligeant à reporter toute activité de signalement et à réorganiser les emplois du temps des équipes.
L’Abes se devait de rendre compte de l’évènement aux établissements membres de ses réseaux. Voici donc le déroulé précis de l’incident, ainsi qu’une explication des mesures de correction prises pour l’avenir.
Les faits marquants
En résumé
Le week-end du 19 et 20 novembre 2022 était consacré à la maintenance informatique annuelle assurée par l’Abes. Cette intervention importante, planifiée plusieurs semaines à l’avance, est généralement réalisée le week-end afin d’éviter de perturber les services aux établissements, du fait qu’elle nécessite une extinction complète des systèmes de l’Abes.
Pendant ce week-end, l’équipe Infrastructure et Réseau de la DSI de l’Abes a réalisé plusieurs opérations techniques qui se sont déroulées avec succès (mises à jour diverses sur les serveurs, ajouts de nouveaux serveurs, redémarrages d’applications, etc.).
C’est au début de la semaine suivante que des dysfonctionnements sont apparus, deux problèmes indépendants ayant très fortement dégradé les performances des applications :
- Un problème sur un port d’un composant physique de l’architecture réseau, faisant le lien entre les serveur applicatifs (le Sudoc en particulier) et les disques durs contenant les données
- Un problème logiciel sur l’architecture Oracle en cluster, suite à la mise à jour des serveurs, qui a nécessité de changer l’architecture pour basculer vers un serveur unique mais mieux dimensionné.
En détail
Lundi 21 novembre 2022
Après la maintenance du week-end, le redémarrage des serveurs et des applications se déroule globalement bien. Cependant, la base XML, point central du SI de l’Abes, connaît des problèmes lors de son redémarrage. Seul un des trois nœuds du cluster de bases de données Oracle a pu redémarrer, ce qui n’empêche pas le fonctionnement de la base mais réduit sa disponibilité.
Suite à la vérification du bon fonctionnement des applications par les responsables informatiques et fonctionnels de l’Abes, un premier incident est détecté qui montre des problèmes de stabilité des applications dépendantes de la base XML. Des débordements de mémoire (out of memory) sont alors détectés au niveau d’Oracle, probablement causés par une surcharge de demande sur l’unique instance fonctionnelle.
En parallèle, des lenteurs sont observées au niveau de WinIBW et du catalogue Sudoc.
Mardi 22 novembre 2022
Les lenteurs Sudoc et Oracle continuent, ce qui provoque des effets de bords importants sur toutes les applications de l’Abes. Malgré les arrêts et réglages des applications et batchs dans l’objectif de réduire la charge de la base Oracle, les tentatives de remise en route des 3 nœuds Oracle restent infructueuses.
Un ticket est déposé chez OCLC, prestataire du Sudoc, afin qu’ils effectuent un diagnostic sur les lenteurs du Sudoc. Leur réponse fait part d’anomalies sur les performances au niveau des disques durs sur lesquels le Sudoc est installé.
Mercredi 23 novembre 2022
Des lenteurs importantes du Sudoc sont observées mais ne semblent pas liées aux dysfonctionnements des 3 nœuds Oracle. Il est décidé de prendre la mesure des bandes passantes et des latences des différents disques durs (qui reposent sur un système de fiber channel et de SAN) au niveau des serveurs du SI : des valeurs anormales sont constatées, mais uniquement sur les disques du Sudoc (entre 60 et 120 fois plus lentes que la normale). Il est procédé à l’arrêt total du Sudoc pendant quelques minutes pour vérifier l’hypothèse que les logiciels du Sudoc puissent être la cause de ces lenteurs du Sudoc.
Les mesures des mêmes bandes passantes des disques indiquent des performances toujours entre 60 et 120 fois moins bonnes que d’habitude, et ce, bien que le Sudoc soit stoppé, ce qui écarte cette hypothèse.
Jeudi 24 novembre 2022
Les lenteurs du Sudoc sont telles que le travail sur WinIBW devient quasi impossible. Les réseaux sont informés de la fermeture du Sudoc le temps de corriger le problème.
En parallèle, une équipe se penche sur la partie Oracle pour tenter de comprendre le problème du cluster. Il est décidé de créer un nouveau serveur Oracle pour réparer le cluster. L’installation de ce nouveau serveur terminée, celui-ci ne parvient cependant pas à intégrer le cluster existant.
Devant cette complexité technique, qui exige des connaissances sur les couches logicielles Grid et ASM d’Oracle, un expert Oracle est sollicité pour assister l’équipe. Celui-ci recommande d’abandonner l’architecture Cluster basée sur les couches Oracle ASM et Grid, et de construire une nouvelle base Oracle sur un seul serveur doté de beaucoup plus de ressources. Les données seront stockées sur un système de fichiers Linux classique et non plus via le Cluster RAC Oracle.
Tout est mis en œuvre pour aller dans cette nouvelle direction. L’installation de la base Oracle est lancée sur une architecture récente (disques NVMe & SSD) conçue pour gérer efficacement ce type de besoin.
De nouveau, la base XML connait des dysfonctionnements avec des temps de réponse assez longs qui provoquent des instabilités des applications. Un message est envoyé au réseau pour indiquer les difficultés. Un redémarrage de l’instance Oracle est effectué permettant de réinitialiser la mémoire et de restaurer partiellement le service.
Vendredi 25 novembre 2022
Côté lenteurs Sudoc, l’équipe infra explore une piste liée à l’observation d’une « tempête sur les switches fibres Brocades », équipements réseaux permettant de relier les serveurs au SAN de l’Abes. Pour creuser cette piste sans risquer de corrompre les données Sudoc, il est décidé d’arrêter techniquement le Sudoc.
Des messages d’erreurs explicites sur un port du brocades sur lequel est branché un des serveurs physiques du Sudoc sont repérés. Des machines virtuelles du Sudoc sont déplacées sur un autre serveur physique afin de libérer celui qui est soupçonné. Après le branchement du serveur physique du port en question, la « tempête de Brocades » se réduit progressivement et les métriques des performances disques du Sudoc sont bonnes.
Il est alors décidé de redémarrer le Sudoc, dont les performances redeviennent normales pour la partie WinIBW. Cependant, le catalogue public Sudoc reste lent avec des erreurs « 500 » fréquentes.
Une analyse plus fine des traces du serveur web du Sudoc public permet de mieux comprendre la nature du problème et de modifier un paramétrage pouvant provoquer ces erreurs 500. Après ces modifications Le Sudoc public fonctionne à nouveau normalement.
Il est décidé de laisser passer le week-end pour confirmer cette stabilité. OCLC est sollicité pour vérifier que tous les voyants sont au vert de leur point de vue également.
Lundi 28 novembre 2022
La réponse d’OCLC en fin de matinée confirme que l’état du Sudoc est au vert. Un message est envoyé aux réseaux de l’Abes indiquant la réouverture des services pour les parties WinIBW et Sudoc.
Vendredi 2 décembre 2022
La nouvelle base Oracle est maintenant installée et un chargement « d’essai » des données de la base XML de production est lancé.
Semaine du 5 au 9 décembre 2022
Une fois la base de données chargée, les tests de synchronisation peuvent commencer pour vérifier la mise à niveau en léger différé avec la base de production afin de ne pas perdre les nouvelles données.
La nouvelle architecture sur laquelle repose la nouvelle base Oracle n’est pas encore complètement mise en service, les dernières opérations d’installation et de mises à jour des équipements sont effectuées.
Lundi 12 décembre 2022
En production, l’unique instance Oracle ne tient pas la charge. La base est redémarrée une nouvelle fois pour rétablir le service. Les utilisateurs sont prévenus et des restrictions d’accès sont mises en place pour laisser le plus possible de ressources aux utilisateurs.
Avant la mise en production de la nouvelle base Oracle, il est indispensable de tester la procédure de migration sur les environnements DEV et TEST. Ce processus prendra un peu de temps (les deux premières semaines de janvier) car les opérations suivantes sont nécessaires :
- Installation des bases de données sur ces environnements
- Chargement des données
- Vérification de l’accès des applications à ces nouvelles bases.
La date cible pour la mise en production est prévue pour la fin de la 3ème semaine de janvier, probablement le vendredi 20 janvier.
Mardi 3 janvier 2023
Au retour de congés, la base XML est de nouveau assez instable.
Mercredi 4 janvier 2023
La base XML est redémarrée afin de résoudre le problème. Le plan initial de migrer vers la nouvelle base Oracle d’ici le 20 janvier est poursuivi, tout en espérant que la base de production restera en service pendant cette période. Les restrictions d’utilisation au sein de l’Abes sont rappelées aux collègues.
Jeudi 5 janvier 2023
Malheureusement, la base XML présente des temps de réponse de plus en plus longs, soit une quasi-indisponibilité des applications qui en dépendent. Pour réparer, il est préconisé un redémarrage complet du serveur pour libérer la mémoire. Cette opération comporte un risque, c’est pourquoi les équipes se préparent également à migrer en urgence si un problème bloquant survenait.
Le redémarrage est planifié pour le lundi suivant, ce qui laisse une journée pour préparer cette étape importante.
Vendredi 6 janvier 2023
L’installation de la nouvelle base Oracle sur l’environnement de DEV et de TEST est terminée. La procédure de migration est mise en œuvre pour que les applications migrent sans incident et sans perte de données. L’équipe s’assure que les sauvegardes des données sont à jour et correctes.
Lundi 9 janvier 2023
Le redémarrage du serveur a échoué, la base Oracle refuse de se monter. Malgré les efforts de l’équipe tout au long de la journée, le problème ne se résout pas. Une réunion de crise se tient vers 17h et il est décidé de changer de stratégie en migrant immédiatement la production vers cette nouvelle architecture.
A cette fin, sont initiées les opérations de chargement et de synchronisation, de redirection des accès des applications vers cette nouvelle base et les tests de bon fonctionnement, ce qui prend la fin de journée et la journée suivante.
Mardi 10 janvier 2023
La nouvelle base est maintenant en ligne et fonctionne efficacement. Cette journée est consacrée aux tests de toutes les applications avec les différents responsables d’application afin de s’assurer de son bon fonctionnement et de l’absence de bugs.
Mercredi 11 janvier 2023
Les derniers problèmes de connexion sont résolus et les utilisateurs informés de la reprise normale des activités. Les sauvegardes sur ce nouvel environnement sont repositionnées afin d’assurer la sécurité des données.
Jeudi 12 janvier 2023
Les temps de réponse sont bons, l’activité normale a pu reprendre.
Une expertise débute pour contrôler et analyser la nouvelle architecture Oracle. En plus de cette expertise, des solutions pour la mise en place d’une base miroir destinée aux requêtes en lecture seront proposées.
Un visuel pour récapituler
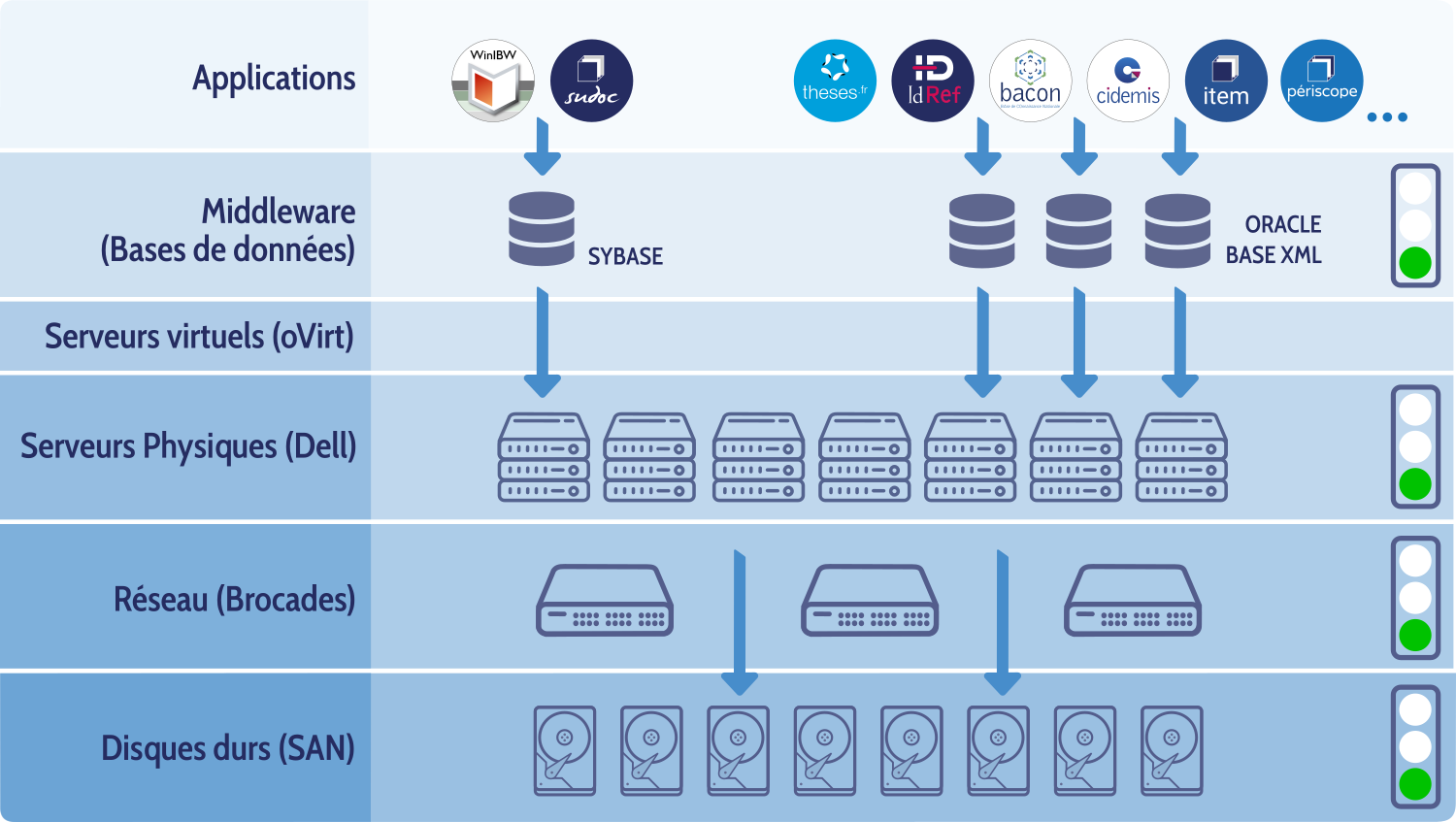

Et la suite ?
Dans un objectif d’amélioration continue, l’Abes a cherché à apprendre de cet incident et décidé des actions suivantes :
- Mise en place d’une base miroir Oracle pour isoler les usages internes des usages des applications ouvertes aux réseaux en production. Cette opération permettra d’éviter que des usages internes gourmands en ressources n’influent sur les performances des applications ouvertes aux réseaux.
- Refonte de l’infrastructure des “Brocades” qui est la couche entre le SAN (disque durs utilisés entre autres par le Sudoc) et les serveurs (par exemple ceux du Sudoc). Cette opération couteuse permettra de fiabiliser cette couche réseau critique.
- Mise à plat de la procédure de gestion des incidents incluant le circuit de communication Abes interne/externe dans le but de l’améliorer.
- Révision des opérations de maintenance annuelles : elles seront découpées en unités de travail plus petites, de façon à limiter le risque d’effets de bord et à faciliter le diagnostic en cas de difficulté.
Merci pour ce retour détaillé sur l’envers du décor, l’exercice de transparence est fort intéressant.