
A la disposition des membres du réseau Sudoc PS, l’application présentée ci-dessous a été conçue par Géraldine Geoffroy (SCD Université Côte d’Azur) et Emmanuelle Rauzy (responsable CR Sudoc PS PACA/Nice ). Qu’elles en soient ici remerciées !
Cette réalisation s’inscrit tout naturellement dans l’esprit d’ouverture des codes sources et de collaborations applicatives porté par l’Abes avec la mise à disposition du code documenté et des consignes d’installation d’une instance locale via le GitHub de l’Abes.
Le contexte
Dans le cadre de sa précédente convention sur objectifs (2018-2020) avec l’Abes, le Centre du Réseau Sudoc PS PACA/Nice s’est concocté un programme ambitieux, basé sur les activités «classiques» d’un CR en terme d’animation de son réseau (visites, formation, communication, prospection), mais également sur un projet de valorisation de deux corpus issus des collections de son périmètre et considérés comme prioritaires :
- le corpus des unicas du CR : il s’agit des titres de périodiques pour lesquels un seul exemplaire est disponible (et localisé dans le Sudoc) dans une des bibliothèques du CR, ce qui confère à celui-ci une responsabilité particulière quant à la qualité des métadonnées signalées
- le corpus des titres de presse locale ancienne : il s’agit des titres de périodiques identifiés par la BnF sur son site dédié de référencement de la presse locale ancienne (ex : BIPFPIG), et qui revêtent, d’un point de vue local, un intérêt scientifique et patrimonial certain.
L’ambition de ce projet était de se doter d’un outil (idéalement d’une application web) d’exploration multi-scalaire, qui permette, au niveau global du CR ainsi que pour chacune des bibliothèques du réseau, de réaliser les opérations suivantes :
- visualiser tout ou partie des 2 ensembles de notices
- croiser les données des corpus afin de :
- visualiser les éventuels recoupements entre corpus et collections conservées (du point de vue d’une ou plusieurs bibliothèques, et d’un point de vue territorial)
- proposer des vues agrégatives où les métadonnées issues de l’environnement Sudoc enrichissent et complètent celles provenant de l’écosystème BnF, et vice-versa
- analyser les métadonnées sur le plan de leur qualité et de leur complétude
- exporter tout ou partie des métadonnées pour constituer des listes de travail ou pouvoir les exposer dans d’autres environnements ou interfaces tierces.
Les problématiques techniques
Voilà pour la théorie, mais quand il s’agit de concrètement passer à l’action, la mise en œuvre de ce programme se décline en réalité en plusieurs phases, et autant de problématiques associées :
- identification des deux corpus : quelle méthodologie appliquer pour discriminer précisément les notices concernées dans les deux réservoirs du Sudoc et de la BnF ? Selon quelles modalités d’exposition et dans quels formats obtenir les métadonnées ? Réaliser des extractions statiques ou dynamiques ?
- stockage des données, modélisation et mises à jour : en fonction de l’étape précédente, peut-on envisager une application complètement dynamique qui interrogerait à la volée les sources de données, ou faut-il penser une phase intermédiaire de stockage des données dans une base de données interne sur laquelle brancher l’application ? Dans la 2ème hypothèse, quel type de base de données choisir en fonction des fonctionnalités attendues ? Comment formaliser les workflows pour permettre l’extraction et le traitement de données, puis l’alimentation de la base de données afin de faciliter les procédures d’actualisation et de mise à jour ?
- application web : quelle architecture et quel langage de programmation utiliser ? Où déposer et versionner le code source ?
Les solutions techniques
Toutes les réponses, mais aussi les tentatives (réussies ou non), les tâtonnements (méthodologiques ou applicatifs) ainsi que les raisons des choix effectués sont détaillées dans une série de billets en mode “carnet de route du projet” sur le blog du CR PACA/Nice
En résumé, voici la façon dont le cœur du dispositif déployé est composé :
- moissonnage des données : via les divers Web services et API à disposition dans les écosystèmes du Sudoc et de la BnF
- stockage les données : choix d’une base de données NoSQL orientée graphe, plus précisément Neo4j, dont le moteur de graphe offre une solution intégrée à la fois pour la récupération des métadonnées, l’exécution des différentes phases de prétraitement, et surtout leur modélisation selon un schéma personnalisé et optimisé quand il s’agira ensuite d’exploiter/parcourir les relations entre données.
Pourquoi Neo4j ?
Dans un système qui stocke nativement les données en structure de graphe, chaque instance d’une entité est représentée par un nœud (au lieu d’une ligne dans une table d’un modèle relationnel) et peut pointer sur un autre nœud via un arc pour symboliser leur relation (au lieu d’une requête de jointure entre tables). Les entités ainsi connectées et représentées sont donc spécifiquement prêtes à être lues et parcourues quel que soit le point de départ (la requête), sachant qu’en outre les SGBD type graphe sont dits « schemaless », c’est-à dire que tous les choix de modélisation élaborés en amont sont possibles et optimisables en fonction des besoins anticipés.
Ainsi par exemple, et pour revenir au projet du CR PACA/Nice, voici le modèle de données élaboré pour stocker les différents jeux de métadonnées convertis en entités et relations :
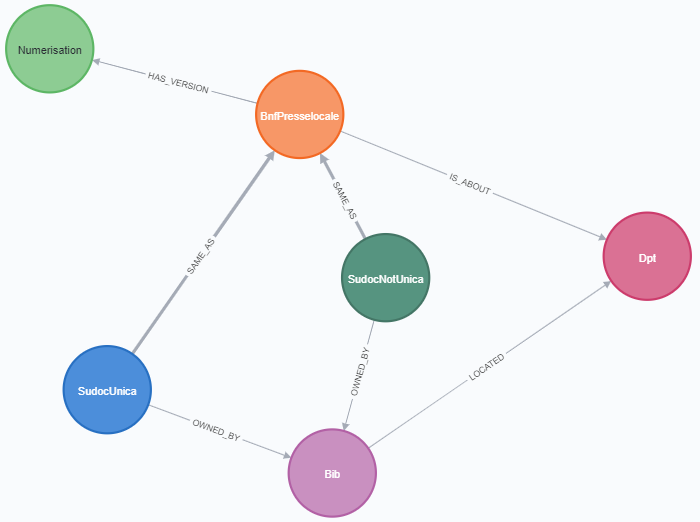
Concernant l’alimentation du graphe et son exploitation, Neo4j est une base de données libre qui offre en plus les spécificités suivantes :
- un langage de requêtes nommé Cypher, relativement simple inspiré de la syntaxe du SQL
- un ensemble de plugins/applications venant étendre les fonctionnalités natives du SGBD, notamment cette librairie qui permet entre autres d’interroger des API REST ou de parser du HTML pour scrapper des pages web
- des drivers d’interfaçage avec des applications tierces, disponibles dans la plupart des langages de développement web et qui facilitent le développement de backend d’application pour l’accès aux données
- [on le signale pour être complet, mais non utilisé ici] des connecteurs permettant d’intégrer dynamiquement les données d’une base Neo4j avec des environnements externes (logiciel BI par exemple), ou à l’inverse de mapper puis charger dans Neo4j les données d’un SGBDR dans une logique ETL.
Dans notre cas, hormis la liste des PPN des notices d’unicas de l’ILN 230 obtenue manuellement à l’aide du service SELF Sudoc, toutes les données nécessaires sont accessibles dynamiquement via les Web services du Sudoc, le SRU de la BnF et par web scrapping du site http://presselocaleancienne.bnf.fr/accueil. Les données sont donc extraites, retraitées, chargées puis liées dans la base de données via des requêtes Cypher successives qui permettent d’alimenter le graphe progressivement selon la logique (simplifiée) suivante :
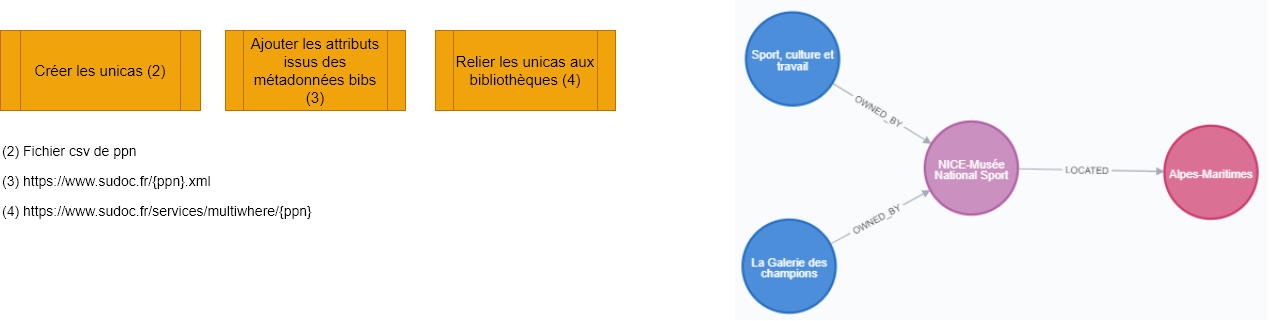
Étape 1 : relations bibliothèques-départements

Étape 2 : relations unicas – bibliothèques-départements
Étape 3 : relations départements-presse locale-numérisation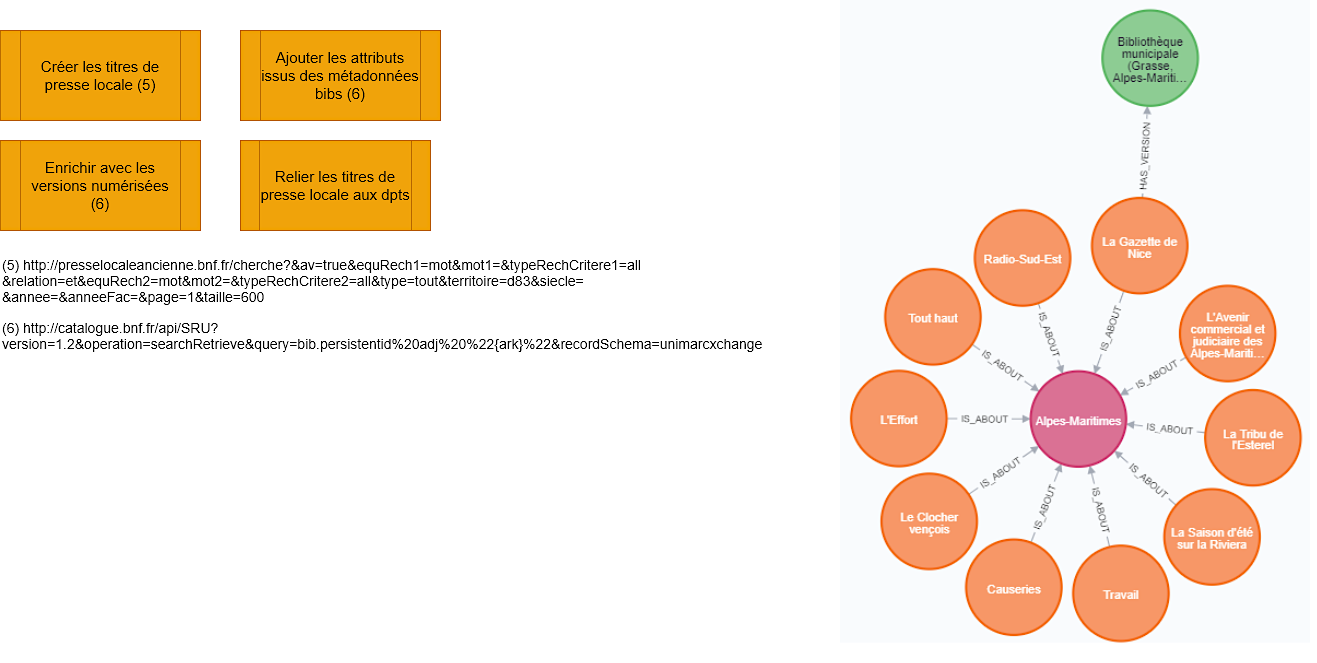
Étape 4 : relations départements-bibliotheques-unicas-presse locale-numérisations (1)-départements(2)
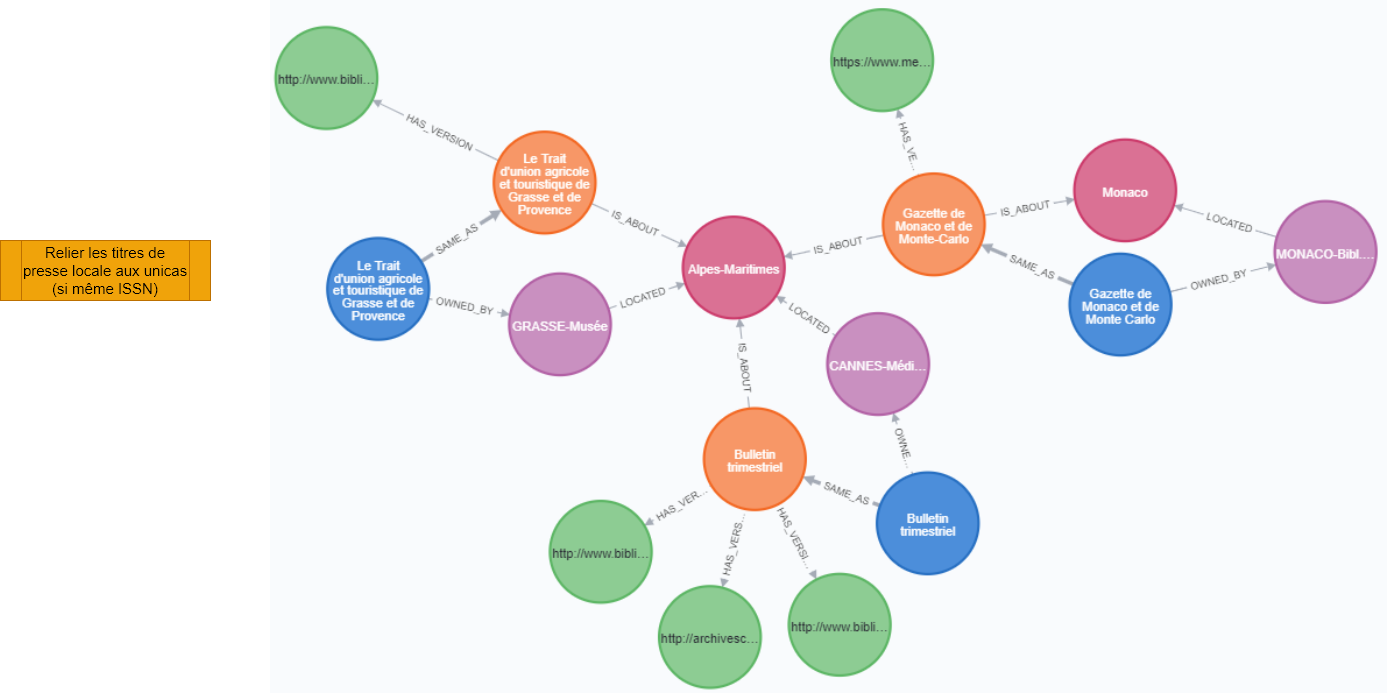
Un dispositif reproductible
Considéré comme prioritaire dès le début du projet, l’un des objectifs consistait à prévoir un dispositif reproductible par d’autres Centres du Réseau Sudoc PS souhaitant le mettre en œuvre avec les données de leur périmètre. A cette fin, la suite des requêtes Cypher est librement accessible et documentée dans ce Gist, et réutilisable par tout CR à condition de les adapter selon les consignes de la documentation, et, bien évidemment, de disposer d’une instance Neo4j.
Pour illustrer ce point, voici des exemples de requêtes en langage Cypher permettant de créer la sous-partie du graphe Bibliothèques -> Département :

Une fois les données modélisées sous forme de réseau selon le schéma précédent qui connecte les bibliothèques, les départements, les unicas, les périodiques de presse locale ancienne (…) par des relations qualifiant une appartenance territoriale, la détention d’une collection, une équivalence entre notices (…), on peut s’affranchir d’un travail de jointure complexe avec des fichiers plats ou des tables relationnelles, en bénéficiant des performances de requêtes type parcours de graphe.
Exemples de requêtes et résultats
- pour obtenir les PPN des notices d’unicas dont les contenus numérisés sont par ailleurs disponibles en ligne
- requête Cypher : MATCH (s:SudocUnica)-[*2]->(n:Numerisation) return s.pp
-
- résultats en Json : [{« s.ppn »: « 244184690 »},{« s.ppn »: « 244184690 »},{« s.ppn »: « 244184690 »},{« s.ppn »: « 037979728 »}, »s.ppn »: « 039140792 »}] »
- pour obtenir les RCR des bibliothèques détenant ces unicas accessibles en ligne :
- requête Cypher : MATCH (b:Bib)–(s:SudocUnica)-[*2]->(n:Numerisation) return b.rcr as rcr,s.ppn as ppn
-
- résultats en Json : [{« rcr »: « 060296201 », »ppn »: « 244184690 »},{« rcr »: « 060296201 », »ppn »: « 244184690 »},{ « rcr »: « 060296201 », « ppn »: « 244184690 »},{ « rcr »: « 991386201 », »ppn »: « 037979728 »},{« rcr »: « 060692301 », »ppn »: « 039140792 »}]
- pour obtenir les titres de presse locale ancienne conservés dans plusieurs bibliothèques :
- requête Cypher : MATCH (b:Bib)<-[o:OWNED_BY]-(s)-[:SAME_AS] ->(bnf:BnfPresselocale) with bnf,collect(b.name) as bibs where size(bibs) > 1 return bnf.titre,bibs
-
- résultats :
[{ « bnf.titre »: « Le Progrès d’Antibes », »bibs »: [« ANTIBES-Mediath.A.Camus », « NICE-Bibl.Chevalier de Cessole »] },
{ « bnf.titre »: « Société centrale d’agriculture, d’horticulture et d’acclimatation de Nice et des Alpes-Maritimes »,
« bibs »: [ « CANNES-Médiathèque municipal », »DRAGUIGNAN-SESA »] },
{ « bnf.titre »: « Bulletin de la Société centrale d’agriculture, d’horticulture et d’acclimatation de Nice et du département des Alpes-Maritimes »,
« bibs »: [« CANNES-Médiathèque municipal », « DRAGUIGNAN-SESA » ] },….]
C’est sur cette base que l’application web développée sous Node.js intègre un backend d’API qui interroge et traverse le graphe de la base de données, puis redistribue les flux de réponses de données vers le frontend, dont les différents composants web assurent la restitution sous forme de tableaux, graphiques en barres et autres visualisations en réseau.
Vers l’infini et au-delà ?
Outre la cartographie précise des deux ensembles de périodiques étudiés, cette application a également servi de support, au sein du CR et en lien avec les bibliothèques du réseau, à un chantier d’amélioration de la qualité bibliographique des notices Sudoc, en s’appuyant sur des requêtes spécifiques permettant par exemple de détecter les notices d’unicas sans ISSN ou d’apporter les corrections nécessaires sur celles comportant des zones 309.
Plus avant, en fournissant une base de travail facilement interrogeable, le fait de disposer d’un tel outil ouvre la voie aux potentiels projets portés par le CR, comme par exemple la mise en place d’un dispositif de conservation partagée de presse locale ancienne ou le repérage de titres pertinents pour des opérations de numérisation.
Géraldine Geoffroy, SCD-BU Université Côte d’Azur, Département Sidoc, chargée d’ingénierie documentaire
Emmanuelle Rauzy, SCD-BU Université Côte d’Azur, Département Sidoc, responsable du CR Sudoc PS PACA/Nice
Pour réutiliser l’application
- l’instance de l’application est librement accessible en ligne : http://sudocps.univ-cotedazur.fr/sudocps-pro-app
- le code de l’application et la documentation associée est disponible sur le Github de l’Abes : https://github.com/abes-esr/sudocps-graph-app
- Exemple de réutilisation : prototype déployé en concertation et avec les données du CR Sudoc PS PACA/Aix-Marseille : https://sudocps-graph-app-marseille.herokuapp.com
Ping : Sudoc-PS » Application Unicas / Presse locale ancienne : grosse actu !