Univ-Droit et IdRef : une coopération ambitieuse et réciproque Auteur/autrice de la publication :Punktauteur Publication publiée :22 janvier 2018 Post category:Non classé Continuer la lectureUniv-Droit et IdRef : une coopération ambitieuse et réciproque
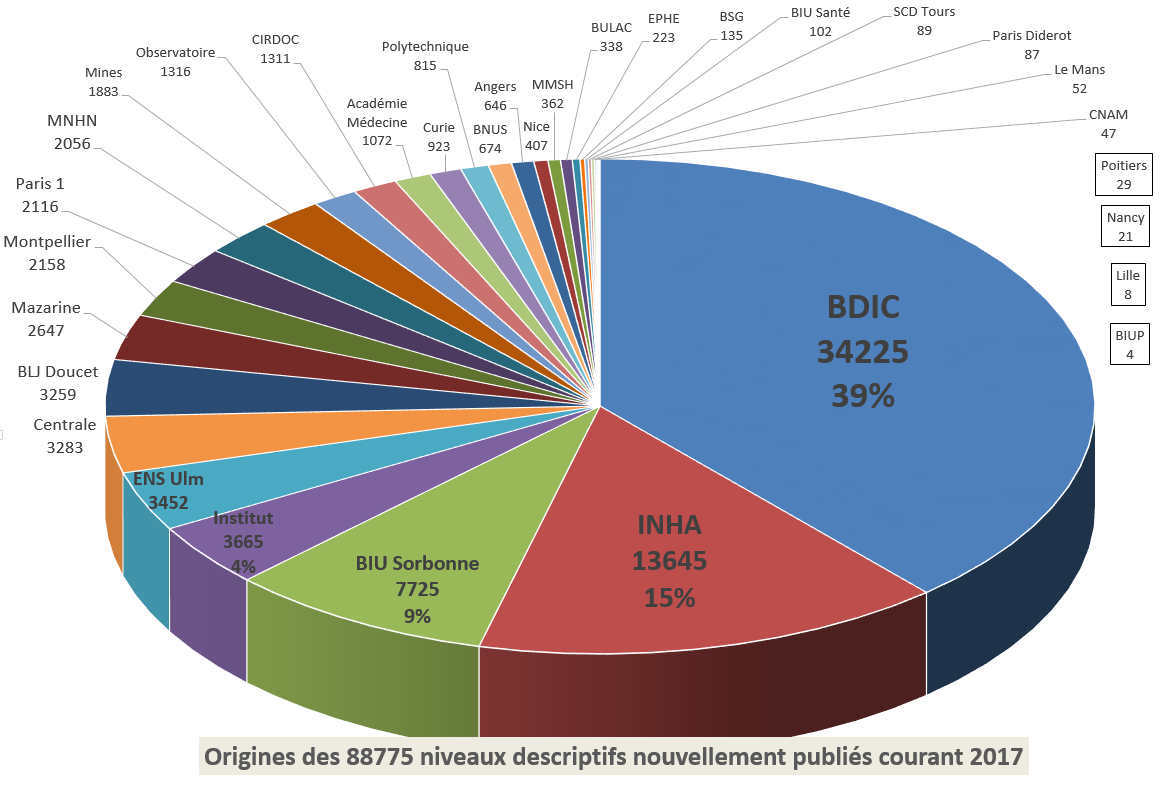
Calames : les statistiques 2017 Auteur/autrice de la publication :Punktauteur Publication publiée :22 janvier 2018 Post category:Calames Continuer la lectureCalames : les statistiques 2017