
Avec près de 80 diffuseurs et plus de 400 bouquets décrits, les données BACON constituent un vivier d’informations que l’on peut exploiter de multiples manières. Non seulement elles sont utiles pour améliorer le signalement de la documentation en ligne, mais elles peuvent de plus être manipulées dans tous les sens, grâce à l’ouverture technique sur laquelle on avait misé dès le début.
L’objet de ce billet est de montrer comment BACON peut répondre à une question fréquemment posée : où se trouve cette revue, chez qui est-elle gratuite, chez qui est-elle payante, et sur quels intervalles chronologiques ?
Cette question a notamment été soulevée sur le blog Biblioweb. Ici, on va s’intéresser au mode de distribution des revues qui par ailleurs sont disponibles sur CAIRN.
Les données de BACON peuvent répondre à toutes ces questions grâce aux informations structurées en KBART v2. On connaît en effet l’état de collection d’une revue (date_first_issue_online – date_last_issue_online), on sait si elle est sur abonnement ou gratuite (access_type) et on sait combien d’années peuvent s’écouler entre la mise en ligne où l’accès est payant et l’ouverture à tous (embargo_info). Il nous suffit ensuite de partir d’une liste d’ISSN, imprimés ou électroniques, qui nous intéressent, utiliser les webservices BACON adéquats et de mouliner le tout.
Les résultats peuvent prendre l’apparence d’un simple tableau, mais dans ce cas précis il est sans doute plus pertinent de voir d’un coup d’œil l’ensemble des informations qui nous intéressent afin d’obtenir quelque chose qui ressemble à ça :
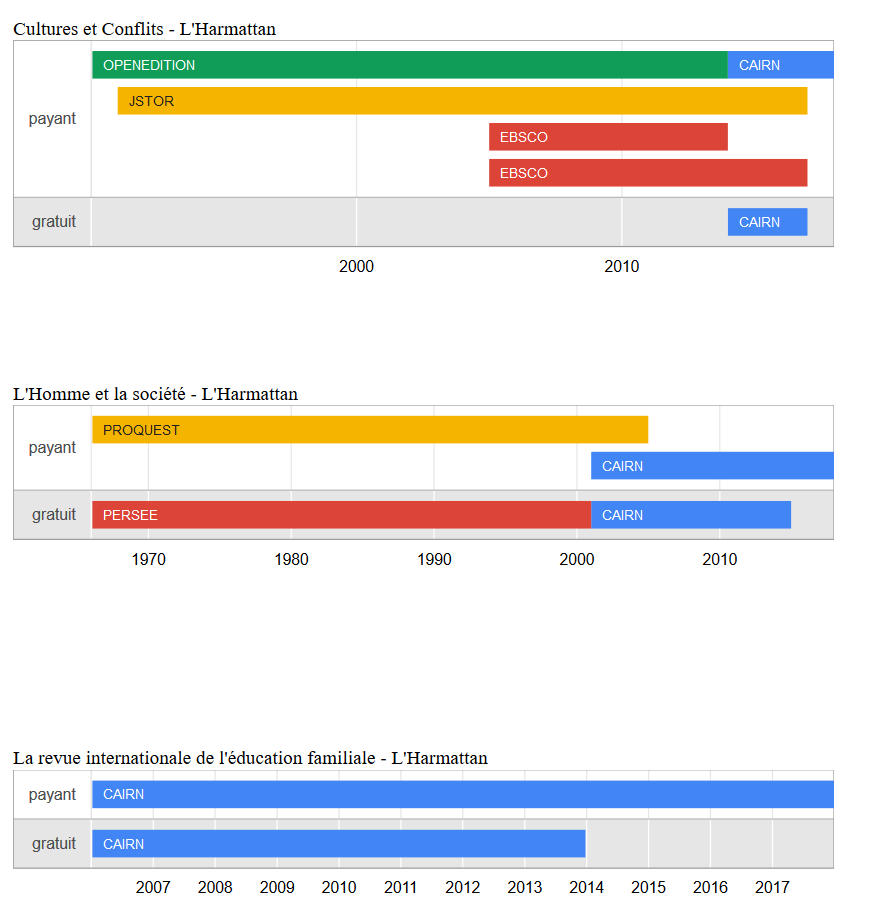
La démarche que je vous propose pour aboutir à ce résultat est une démarche « bidouille » : on trouve quelque chose qui se rapproche de ce que l’on souhaite faire, on regarde comment ça marche, on l’adapte avec les outils à sa disposition et/ou que l’on maîtrise. En l’occurrence, tout ce qui sera montré ici sera fait avec OpenRefine.
Le modèle à trouver et à comprendre
C’est sans doute la partie la plus simple. En parlant autour de moi de cette idée de visualisation, un collègue m’a tout de suite orienté vers ceci https://developers.google.com/chart/interactive/docs/gallery/timeline, une bibliothèque javascript issue de Google Charts qui permet justement de créer des frises chronologiques. L’idée générale est donc de créer une page html, lisible par n’importe quel navigateur, qui contiendra les données que l’on veut afficher ainsi que le code pour les mettre en forme. On ne s’occupera que de la partie « données ». Tout le reste sera géré par le code que l’on se contentera de recopier (mais qu’il faut comprendre un tout petit peu).
L’exemple ci-dessous correspond exactement à ce que l’on veut faire : on veut pouvoir grouper par type (ici Président, Vice Président et Secrétaire d’Etat mais pour nous Gratuit et payant) des états de collection correspondant à différents fournisseurs (ici Washington, Adams, Jefferson, pour nous Persée, Open Edition, CAIRN par exemple). La structure du script n’est pas difficile à comprendre :
<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script>
<div id="example3.1" style="height: 200px;"></div>
<script type="text/javascript">
google.charts.load("current", {packages:["timeline"]});
google.charts.setOnLoadCallback(drawChart);
function drawChart() {
var container = document.getElementById('example3.1');
var chart = new google.visualization.Timeline(container);
var dataTable = new google.visualization.DataTable();
dataTable.addColumn({ type: 'string', id: 'Position' });
dataTable.addColumn({ type: 'string', id: 'Name' });
dataTable.addColumn({ type: 'date', id: 'Start' });
dataTable.addColumn({ type: 'date', id: 'End' });
dataTable.addRows([
[ 'President', 'George Washington', new Date(1789, 3, 30), new Date(1797, 2, 4) ],
[ 'President', 'John Adams', new Date(1797, 2, 4), new Date(1801, 2, 4) ],
[ 'President', 'Thomas Jefferson', new Date(1801, 2, 4), new Date(1809, 2, 4) ],
[ 'Vice President', 'John Adams', new Date(1789, 3, 21), new Date(1797, 2, 4)],
[ 'Vice President', 'Thomas Jefferson', new Date(1797, 2, 4), new Date(1801, 2, 4)],
[ 'Vice President', 'Aaron Burr', new Date(1801, 2, 4), new Date(1805, 2, 4)],
[ 'Vice President', 'George Clinton', new Date(1805, 2, 4), new Date(1812, 3, 20)],
[ 'Secretary of State', 'John Jay', new Date(1789, 8, 25), new Date(1790, 2, 22)],
[ 'Secretary of State', 'Thomas Jefferson', new Date(1790, 2, 22), new Date(1793, 11, 31)],
[ 'Secretary of State', 'Edmund Randolph', new Date(1794, 0, 2), new Date(1795, 7, 20)],
[ 'Secretary of State', 'Timothy Pickering', new Date(1795, 7, 20), new Date(1800, 4, 12)],
[ 'Secretary of State', 'Charles Lee', new Date(1800, 4, 13), new Date(1800, 5, 5)],
[ 'Secretary of State', 'John Marshall', new Date(1800, 5, 13), new Date(1801, 2, 4)],
[ 'Secretary of State', 'Levi Lincoln', new Date(1801, 2, 5), new Date(1801, 4, 1)],
[ 'Secretary of State', 'James Madison', new Date(1801, 4, 2), new Date(1809, 2, 3)]
]);
chart.draw(dataTable);
}
</script>
Les éléments qui se rapportent aux données sont :
- Un « id », que l’on trouve à deux endroits
-
var container = document.getElementById('example3.1');) -
<div id="example3.1" style="height: 200px;">
- Le premier permet de lier un identifiant au set de données que l’on va inscrire, le deuxième permet d’afficher notre frise. Dans notre cas on a besoin d’un id par revue.
-
- La description de nos colonnes, par exemple ici dataTable.addColumn({ type: ‘string’, id: ‘Position’ }); Il faut donc donner le type d’information (‘string’, simples chaînes de caractères ou ‘date’) et le nom (id) de la colonne. Nous aurons besoin d’une colonne ‘prix’ (payant/gratuit), d’une colonne ‘diffuseur’ et de deux colonnes de date (début et fin). Ces informations seront toujours les mêmes, quelle que soit la revue.
- Nos données à proprement parler se trouvent après dataTable.addRows, par exemple [ ‘President’, ‘George Washington’, new Date(1789, 3, 30), new Date(1797, 2, 4) ]. Dans notre cas ce sera par exemple [ ‘payant’, ‘CAIRN’, new Date(2008, 0, 0), new Date(2016, 11, 30) ]. Dans les objets dates Javascript, les mois et les jours sont indexés en partant de 0. Le premier janvier est donc ‘0,0’, le 31 décembre ‘11,30’).
La bibliothèque se charge de tout mettre dans l’ordre, il n’est donc pas nécessaire de grouper les « gratuits » ensemble ni de mettre les différents éléments dans l’ordre chronologique.
Si l’on reprend notre structure, on cherche donc à avoir pour chaque revue (les variables sont entre ##):
#titre_revue# – #editeur_scientifique#<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script>
<div id="#ISSN_revue1#'" style="height: 200px;"></div>
<script type="text/javascript">
google.charts.load("current", {packages:["timeline"]});
google.charts.setOnLoadCallback(drawChart);
function drawChart() {
var container = document.getElementById('#ISSN_revue1#');
var chart = new google.visualization.Timeline(container);
var dataTable = new google.visualization.DataTable();
dataTable.addColumn({ type: 'string', id: 'prix' });
dataTable.addColumn({ type: 'string', id: 'diffuseur' });
dataTable.addColumn({ type: 'date', id: 'debut' });
dataTable.addColumn({ type: 'date', id: 'fin' });
dataTable.addRows([
[ '#prix#', '#diffuseur#', new Date(#debut#, 0, 0), new Date(#fin#, 11, 30) ],
[ '#prix2#', '#diffuseur2#', new Date(#debut2#, 0, 0), new Date(#fin2#, 11, 30) ]
]);
chart.draw(dataTable);
}
</script>
La page finale que l’on cherche à générer sera un tableau html où chaque ligne comportera le code correspondant à une revue.
Préparer la requête BACON
On veut maintenant trouver une liste de toutes les revues distribuées par CAIRN. BACON est bien entendu le bon endroit où chercher. Un rapide tour sur l’interface https://bacon.abes.fr permet de récupérer ce qui nous intéresse. En allant sur « Exporter », en faisant une recherche par fournisseur puis en décochant « Bouquet courant », on obtient la liste complète des titres de revues disponibles sur CAIRN. Un clic sur la flèche rose permet de télécharger le fichier.
Dans le cas des revues à barrière mobile (les dernières années sont payantes, les années antérieures deviennent progressivement gratuites au bout de 2, 4, 5 ans voire plus) les master lists BACON proposent deux lignes par revue : une ligne décrivant la partie gratuite, une autre la partie sur abonnement. Le champ « embargo_info » permet de décrire la durée au bout de laquelle la revue devient gratuite.
Après avoir ouvert le fichier (en vérifiant bien que le séparateur compris est la tabulation et que l’encodage est l’UTF8) nous allons donc supprimer les doublons. Nous allons utiliser OpenRefine pour lancer cette opération. Le chargement du fichier s’effectue en cliquant sur « parcourir » et en sélectionnant le fichier CAIRN qui nous intéresse. Après un clic sur « next », OpenRefine propose quelques options d’import. Il faut bien vérifier que l’encodage est UTF8, puis on peut cliquer sur « create project ». On arrive alors sur l’interface de travail d’OpenRefine, nous présentant une vue de nos données de manière tabulaire.
Nous allons utiliser la fonction « Blank down », qui permet de supprimer la valeur d’une cellule si la valeur de la cellule précédente est identique. Les fichiers KBART étant classés dans l’ordre alphabétique du titre, on sait que ce cas de figure se présentera pour le fichier CAIRN.
En cliquant sur la flèche à gauche de l’en-tête de colonne « publication_title », le menu déroulant propose de sélectionner « Edit cells » puis « Blank down ». Un clic et toutes les cellules en doublons disparaissent.
Pour supprimer les lignes correspondantes, il faut faire une facette permettant de faire remonter les cellules vides. Pour ce faire, il faut cliquer sur la même flèche à gauche de « publication_title », puis cliquer sur « Facet », puis sur « Customized facets » et enfin sur « Facet by blank ».
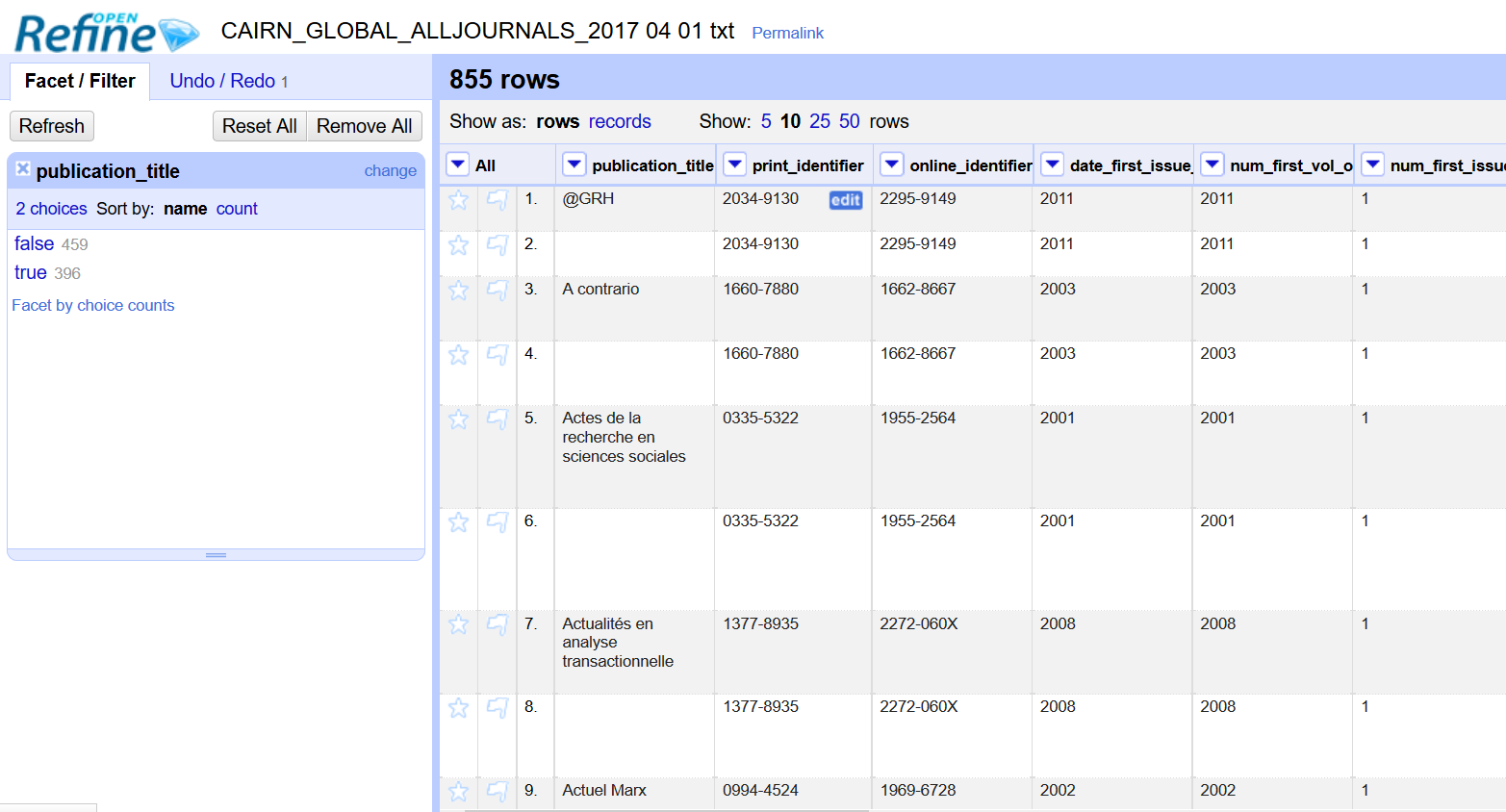
Dans le panneau de gauche apparaît alors les facets. « False » signifie que la cellule n’est pas vide, « True » qu’elle l’est bien. On va donc cliquer sur « True », ce qui a pour conséquence de n’afficher que les lignes qui ont un « publication_title » vide. Il faut enfin cliquer sur la flèche à gauche de « All », aller sur « Edit rows » et enfin sur « Remove all matching rows ».
Tout disparaît alors de votre vue tabulaire, mais pas de panique : en supprimant la facette (petite croix à gauche du titre de la facette) apparaissent toutes les lignes, sans aucun doublon.
On a besoin ensuite d’être sûr d’avoir une colonne avec un identifiant à chaque ligne. Ce n’est pas le cas ici puisque certaines revues n’ont pas d’ISSN papier, uniquement un ISSN électronique. On va donc créer une colonne qui donnera tout le temps l’ISSN papier et qui mettra un eISSN s’il n’y a pas d’autre identifiant.
La procédure est la suivante :
- Cliquez sur la flèche à gauche de l’étiquette de colonne « print_identifier »
- Sélectionnez « Edit Column »> « Add column based on this column… »
- Attribuez un nom à la nouvelle colonne (par exemple « ISSN ») dans le champ « New column name »
- Entrez dans le champ « Expression » le code suivant :
-
if(isBlank(value),cells['online_identifier'].value,value)
- Ce code regarde si le champ « print_identifier » est vide ; si c’est le cas, il ajoute la valeur du champ « online_identifier » ; si ce n’est pas le cas, il conserve la valeur d’origine
-
Lancer et traiter la requête BACON
Nous disposons d’une liste d’ISSN sur laquelle nous allons pouvoir utiliser le webservice id2kbart. Ce webservice permet de connaître l’ensemble des packages où figure un périodique donné en fonction de son ISSN (version « papier » ou version électronique) et remonte l’ensemble des informations KBART correspondantes. Le webservice n’interroge que la version la plus à jour de chaque package.
L’étape suivante va consister à lancer le webservice sur toutes les lignes. Rien de plus simple :
- Cliquez sur la flèche à gauche de l’étiquette de colonne « issn ».
- Sélectionnez « Edit Column »> « Add column by fetching URL… »
- Attribuez un nom à la nouvelle colonne (“BACONjson” par exemple) ») dans le champ « New column name »
- Mettez le « Throttle delay » à 5 millisecondes
- Entrez dans le champ « Expression » le code suivant :
-
"https://bacon.abes.fr/id2kbart/"+value+".json"
- Ce code va prendre la valeur de la cellule id et va lui concaténer par un + les informations permettant de construire l’URL d’interrogation du webservice
-
- Allez prendre un café. Ça va être LONG.
Le json récupéré ressemble à ceci : https://bacon.abes.fr/id2kbart/1293-6146.json
Tout cela est très verbeux car toutes les informations contenues dans la ligne KBART sont remontées, et cela autant de fois qu’il y a de bouquets dans lesquels se trouve le titre. La prochaine opération consiste donc à parcourir le json pour ne sélectionner que les informations qui nous intéressent.
La réponse est typiquement un objet JSON « bacon » dont le contenu est compris entre accolades et à l’intérieur duquel se trouve un tableau « query » qui contient lui-même, entre crochets carrés, un objet « id » (ISSN) et autant d’objet « provider » qu’il y a de bouquets où se trouve la revue dont l’ISSN est interrogé.
Le problème est que le code json est structuré de manière différente en fonction du nombre d’éléments correspondant à la requête.
Par exemple, s’il y a une seule ligne KBART correspondant à un identifiant dans un paquet donné, « kbart » est un objet json contenant un objet « element » décrit par des paires clés-valeurs (par exemple « publication_title »: « Mille huit cent quatre-vingt-quinze ») séparées entre elles par des virgules et encadrées par des accolades, comme le montre l’exemple ci-dessous :
"provider": {
"name": "CAIRN",
"package": "CAIRN_COUPERIN_REVUES-HUMANITES_2016-09-15",
"kbart": {
"element": {
"publication_title": "Mille huit cent quatre-vingt-quinze",
"print_identifier": "0769-0959",
"online_identifier": "1960-6176",
[…]
"access_type": "P"
}
En revanche, s’il y a deux lignes correspondant au même identifiant, comme c’est le cas dans les master lists, « kbart » devient un tableau contenant deux objets « elements », comme ci-dessous :
"provider": {
"name": "CAIRN",
"package": "CAIRN_GLOBAL_ALLJOURNALS_2016-11-15",
"kbart": [{
"element": {
"publication_title": "Mille huit cent quatre-vingt-quinze",
"print_identifier": "0769-0959",
"online_identifier": "1960-6176",
[…]
"access_type": "F"
}
}, {
"element": {
"publication_title": "Mille huit cent quatre-vingt-quinze",
"print_identifier": "0769-0959",
"online_identifier": "1960-6176",
[…]
"access_type": "P"
}
}]
}
}
On pourrait faire un seul script parcourant le json qui prendrait en compte tous les cas de figure (si « kbart » est un tableau tu fais ça, si « kbart » est un objet tu fais autre chose) mais on peut également faire les choses en plusieurs fois et combiner les résultats, comme le permet Openrefine.
On souhaite avoir par bouquet une réponse sous cette forme, et séparer chaque bloc par un point-virgule :
« Name » : « date_first_issue_online »-« date_last_issue_online »:« embargo_info»-« access_type»
Soit par exemple « OPENEDITION:2000-2012:P36M-P ; »
On va donc d’abord créer une colonne à partir de la colonne BACONjson (flèche descendante à gauche du nom puis « Edit column » et « Add column based on this column »), appeler cette colonne « parse1 » et appliquer le script suivant :
join(forEach(value.parseJson().bacon.query,v,v.provider.name+':'+v.provider.kbart.element.date_first_issue_online+ '-'+v.provider.kbart.element.date_last_issue_online+':'+v.provider.kbart.element.embargo_info+'-'+v.provider.kbart.element.access_type),";")
Décortiquons un peu :
« Value » est la variable comprenant l’ensemble de la cellule qui nous intéresse. On dit donc au script de parser cette variable écrite en json (value.parseJson()) en remontant le contenu de l’objet query inclus dans l’objet bacon. Comme query est un tableau contenant plusieurs objets on doit faire un « forEach » permettant de le parcourir. On crée ensuite une variable (ici appellée « v », mais on peut l’appeler comme on veut) qui prendra la valeur attachée à la clef « name » contenue dans l’objet « provider », concatène avec « : », ajoute la valeur attachée à la clef « date_first_issue_online » contenue dans l’objet « element » lui-même contenu dans l’objet « kbart » à son tour contenu dans l’objet provider. Le reste du code est à l’avenant. On obtient donc lors du premier passage de l’itération une réponse sous forme de tableau ressemblant à ça :
[OPENEDITION:2000-2012:P36M-P]
Un « forEach » renverra autant de tableaux que de réponses potentielles. Pour les manipuler, la forme tableau n’est pas adaptée. Il faut donc les transformer en chaîne de caractères. C’est là qu’intervient la première instruction « join », qui va concaténer les différents éléments du tableau au moyen d’un point-virgule, comme on le lui indique par le dernier argument du script.
La réponse visible dans Refine ressembera donc à ça :
Object does not have any field, including provider;CAIRN:2003-null:null-P;Object does not have any field, including element;CAIRN:2003-null:null-P;CAIRN:2003-null:null-P;CAIRN:2003-null:null-P;EBSCO:2007-2015:null-P
A chaque fois que le script tombe sur une expression qu’il ne peut parser il l’indique. La réponse commencera systématiquement par « Object does not have any field, including provider » dans la mesure où le script tombe d’abord sur un objet contenant la paire clef/valeur « id » avant de tomber sur l’objet valeur qui nous intéresse. On s’occupera plus tard de supprimer toutes les mentions inutiles.
On peut ensuite toujours s’appuyer sur la colonne « BACON_json » pour créer les colonnes « parse2 » et « parse3 » afin de pouvoir traiter les cas décrits ci-dessus où le json n’a pas exactement la même tête. On aura donc les scripts suivants :
join(forEach(value.parseJson().bacon.query,v,v.provider.name+':'+v.provider.kbart[0].element.date_first_issue_online+'-'+v.provider.kbart[0].element.date_last_issue_online+':'+v.provider.kbart[0].element.embargo_info+'-'+v.provider.kbart[0].element.access_type),";")
Ici « kbart » est un tableau dont on ne récupère que les valeurs contenues dans la première série d’objet (d’où le [0] puisqu’en json on commence à compter à partir de 0). On sait en effet que c’est dans cette première série que l’on aura les informations concernant l’accès gratuit à la revue, et c’est ça qui nous intéresse.
value.parseJson().bacon.query.provider.name+':'+value.parseJson().bacon.query.provider.kbart.element.date_first_issue_online+'-'+value.parseJson().bacon.query.provider.kbart.element.date_last_issue_online+':'+value.parseJson().bacon.query.provider.kbart.element.embargo_info+'-'+value.parseJson().bacon.query.provider.kbart.element.access_type
Ici il n’y a qu’une valeur possible (il s’agit de revue en OA qui ne sont présentes dans aucun bouquet), donc pas de tableau à parcourir.
L’étape suivante consiste à concaténer ligne à ligne l’ensemble des valeurs parse1, parse2 et parse3 afin d’opérer ensuite toute une série de traitement.
On va donc créer une colonne à partir de parse3, l’appeler parsefinal et appliquer le script suivant :
forNonBlank(value,v,v,cells['parse1'].value+','+cells['parse2'].value)
Le script regarde si la valeur de « parse3 » existe. Si c’est le cas, il l’associe à la variable v (le premier « v » de l’expression), puis l’affiche (le deuxième « v » de l’expression). Sinon, il affiche le quatrième argument, soit les valeurs concaténées par une virgule de « parse1 » et « parse2 ».
On a donc quelque chose comme ça :
Object does not have any field, including element;CAIRN:2008-null:P5Y-F,Object does not have any field, including provider;CAIRN:2008-null:null-P;CAIRN:2008-null:null-P
Avant de passer aux choses sérieuses, on va enfin nettoyer un petit peu les résultats afin notamment de pouvoir faciliter les calculs que nous allons faire sur les couvertures chronologiques.
Je passe rapidement sur la suppression des embargos relatifs aux revues OpenEdition. Ces embargos sont faux et n’ont pas encore été corrigés par l’éditeur à l’heure où j’écris ce texte. Il faut donc les supprimer pour éviter toute incohérence.
Nous allons tout d’abord remplacer les mentions « F » et « P » par « gratuit » et « payant ». Un simple script comme ci-dessous fait l’affaire. Pour l’appliquer, il faut aller sur la colonne « parsefinal » puis « Edit cells » et « transform » :
value.replace('-F','-gratuit')
Dans un fichier KBART, une revue dont le dernier fascicule est accessible n’a pas de date de fin explicitement indiqué. Nous allons remédier à cela grâce à l’expression suivante :
value.replace('-null','-2017')
Nous allons enfin transformer la mention d’embargo en un simple chiffre. En effet, les revues gratuites avec barrière mobile n’ont normalement pas de date de fin dans les fichiers KBART. Pour connaître la date effective du dernier fascicule librement accessible, il faut soustraire le nombre d’années d’embargo à la date de l’année en cours. Pour transformer une expression du type P2Y, P4Y ou P10Y nous allons utiliser des expressions régulières au sein du script ci-dessous :
value.replace(/(P)(\d+)(Y)/,'$2')
Les expressions régulières permettent de repérer un motif et d’opérer des traitements sur celui-ci. Dans openrefine, les expressions régulières sont encadrées de //. Ici l’expression est assez facile à comprendre : on recherche une chaîne qui contient d’abord un P, puis un ou plusieurs chiffres (\d est un raccourci qui désigne n’importe quel chiffre, + indique qu’il y en a au moins un), puis un Y. Le script remplace ensuite toute l’expression par le 2e élément (eh oui, en expressions régulières on compte à partir de 1…), à savoir le chiffre.
Toujours dans cette idée, nous allons convertir les embargos exprimés en mois en embargos exprimés en années. Bien évidemment, on perd en précision ce que l’on gagne en facilité de manipulation. On utilise alors une expression du type :
value.replace('P24M', 'P2Y')
Normalement, dans notre expression, ‘null’ ne désigne maintenant que des titres qui n’ont pas d’embargo. Nous allons donc transformer cette chaîne en chiffre :
value.replace('null', '0')
Maintenant, notre expression ressemble à ça :
Object does not have any field, including element;CAIRN:2008-2017:5-gratuit,Object does not have any field, including provider;CAIRN:2008-2017:0-payant;CAIRN:2008-2017:0-payant
Préparer la visualisation
Nous avons tous les éléments pour la transformer assez facilement en :
[ 'payant', 'CAIRN', new Date(2008, 0, 0), new Date(2017, 11, 30) ], [ gratuit, 'CAIRN', new Date(2008, 0, 0), new Date(2012, 11, 30) ]
Jusqu’à présent, nous avons utilisé un langage de script propre à Openrefine qui s’appelle GREL. Ce langage est très facile d’usage et efficace pour les manipulations simples. Dans notre cas, nous avons besoin de quelque chose d’un peu plus poussé, notamment pour la manipulation des expressions régulières. Nous allons donc utiliser le langage jython, proche du python, qui est l’un des langages nativement intégré à Openrefine. Le script en question étant assez long, les commentaires se font au fur et à mesure. Ces commentaires sont intégrés au code et se manifestent par un # en tête de chaque ligne de commentaire.
import re
#on importe la bibliothèque re, qui comporte les fonctions dont on a besoin
p = re.compile(ur'([A-Z]+:[0-9]{4}-[0-9]{4}:[0-9]{1,2}-[a-z]{6,7})')
#ici, on crée une variable avec le motif de ce que l'on cherche codé comme une "expression régulière"
#[A-Z]+: signifie "trouve moi toutes les chaînes qui ont une ou plusieurs (+) lettres en majuscules([A-Z]) puis deux points (:) par exemple "CAIRN:"
# [0-9]{4}-[0-9]{4}: signifie "trouve moi toutes les chaînes ayant 4({4}) chiffres([0-9]), un tiret(-), et 4 chiffres puis deux points (:) par exemple "2008-2017:"
#[0-9]{1,2}- signifie "trouve moi toutes les chaînes sur 1 à 2 ({1,2}) chiffres ([0-9]) puis un tiret (-) par exemple 5-
#[a-z]{6,7} signifie "trouve moi une chaîne de 6 à 7 ({6,7}) lettres en minuscule [a-z] par exemple "payant" (l'autre valeur étant "gratuit").
#L'expression régulière permet donc de ne prendre en considération que les chaînes qui ressemblent à CAIRN:2008-2017:0-payant ou CAIRN:2008-2017:5-gratuit
reg=re.findall(p, value)
#Recherche toutes les chaînes qui correspondent à l'expression régulière dans "value" qui correspond à tout ce que contient la cellule traitée. Le résultat est une liste. Dans notre exemple ['CAIRN:2008-2017:5-gratuit','CAIRN:2008-2017:0-payant','CAIRN:2008-2017:0-payant']
liste_ec=sorted(list(set(reg)))
#On transforme une première fois la liste en set afin de supprimer les doublons (set(reg)), puis on en refait une liste (list(set(reg)) que l'on trie (sorted) et on attribue le tout à la variable liste_ec. Il est indispensable de disposer d'une liste afin de pouvoir isoler et traiter individuellement chaque élément de la liste, ce qui ne serait pas possible avec une chaîne de caractères simple. Le résultat est donc ['CAIRN:2008-2017:5-gratuit','CAIRN:2008-2017:0-payant']
for i in range(0, len(liste_ec)):
#on parcourt ensuite tous les éléments de la liste en partant du premier élément de la liste (0), jusqu'à son dernier qui a un numéro d'ordre qui correspond à la longueur de la liste (len(liste_ec)). On va récupérer un par un chaque élément qui nous intéresse (éditeur, état de collection, nombre d'années d'embargo, mode d'accès).
regxnom = re.compile(ur'([A-Z]+):[0-9]{4}-[0-9]{4}:[0-9]{1,2}-[a-z]{6,7}')
#on reprend la même expression régulière que ci-dessus, mais avec une grosse différence : on entoure de parenthèses l'expression que l'on veut faire remonter, ici le nom de l'éditeur.
nom=re.findall(regxnom,liste_ec[i])
#Recherche tous les résultats correspondant à l'expression régulière à l'endroit de la liste où l'on se trouve (liste_ec[i])
stringnom=":".join(nom)
#Il ne peut y avoir qu'un seul éditeur par expression, on n'a donc normalement pas besoin de concaténer plusieurs valeurs (ce que fait le ":".join qui concatène en séparant par deux points). Mais le résultat d'un re.findall est une liste, et j'ai besoin d'une simple chaîne de caractère (string). C'est une manière d'y arriver. Il y a sans doute des manières plus élégantes.
regxdatedeb = re.compile(ur'[A-Z]+:([0-9]{4})-[0-9]{4}:[0-9]{1,2}-[a-z]{6,7}')
#mêmes opérations pour la date de début
datedeb=re.findall(regxdatedeb,liste_ec[i])
stringdatedeb=":".join(datedeb)
regxdatefin = re.compile(ur'[A-Z]+:[0-9]{4}-([0-9]{4}):[0-9]{1,2}-[a-z]{6,7}')
#mêmes opérations pour la date de fin
datefin=re.findall(regxdatefin,liste_ec[i])
stringdatefin=":".join(datefin)
regxprix = re.compile(ur'[A-Z]+:[0-9]{4}-.{4}:[0-9]{1,2}-([a-z]{6,7})')
#mêmes opérations pour gratuit/payant
prix=re.findall(regxprix,liste_ec[i])
stringprix=":".join(prix)
regxemb = re.compile(ur'[A-Z]+:[0-9]{4}-.{4}:([0-9]{1,2})-[a-z]{6,7}')
#mêmes opérations pour le nombre d'années d'embargo
emb=re.findall(regxemb,liste_ec[i])
stringemb=":".join(emb)
liste_ec[i]='[\''+stringprix+'\',\''+stringnom+'\', new Date ('+stringdatedeb+',0,0), new Date ('+str(int(stringdatefin)-int(stringemb))+',11,30)]'
#on concatène tous les éléments afin que cela ressemble à l'expression que l'on veut écrire. On raffine en calculant la date de fin en fonction de l'embargo (qui est à 0 pour les titres payants) en transformant en nombre entier la date de fin ((int(stringdatedefin)) et le nombre d'années d'embargo, en soustrayant le deuxième au premier et en reconvertissant le tout en chaîne de caractère (str).
# On arrive à ça, sous la forme d'une liste : ['['payant','CAIRN', new Date (2008,0,0), new Date (2017,11,30)]','['gratuit','CAIRN', new Date (2008,0,0), new Date #(2012,11,30)]']
liste_script=','.join(liste_ec)
#Afin de pouvoir utiliser ces informations, on a besoin de les retransformer en chaîne de caractères. Dans le modèle de script pour obtenir une frise chronologique, on voit que chaque élément doit être séparé par une virgule, d'où le ','.join.
return liste_script
#La fonction return permet l'affichage, on obtient donc la chaîne ['payant','CAIRN', new Date (2008,0,0), new Date #(2016,11,30)],['gratuit','CAIRN', new Date (2008,0,0), new Date (2011,11,30)]
L’avant dernière étape consiste à habiller les expressions que l’on a générées avec le reste du script présenté en début de billet qui s’occupe de l’affichage de la frise chronologique en tant que tel. On va donc transformer notre cellule avec l’expression suivante (à nouveau en GREL) :
cells['publication_title'].value+' - '+cells['publisher_name'].value+ '<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script> <div id="' +cells['issn'].value+ '" style="height: 280px ; width:100%"></div> <script type="text/javascript"> google.charts.load("current", { "packages": ["timeline"] }); google.charts.setOnLoadCallback(drawChart); function drawChart() { var container = document.getElementById("' +cells['issn'].value+ '"); var chart = new google.visualization.Timeline(container); var dataTable = new google.visualization.DataTable(); dataTable.addColumn({ type: "string", id: "prix" }); dataTable.addColumn({ type: "string", id: "titre" }); dataTable.addColumn({ type: "date", id: "Start" }); dataTable.addColumn({ type: "date", id: "End" }); dataTable.addRows([' +value+ ']); chart.draw(dataTable); } </script>'
Il ne nous reste plus qu’à exporter le résultat. On peut au préalable faire un tri par exemple sur la colonne publisher_name afin de regrouper par éditeur (flèche à gauche de publisher_name puis clic sur Sort, puis encore clic sur Sort qui apparaît juste au-dessus des en-têtes de colonnes et clic sur « Reorder rows permanently).
Pour exporter le résultat en une page html, il convient de cliquer sur Export puis « Custom tabular exporter ». Nous n’allons sélectionner que la colonne qui nous intéresse (de-select all puis clic sur la colonne qui a la version finale du script), décocher la case « output colum headers », puis dans l’onglet « Download » sélectionner « html table » dans « other formats », et enfin cliquer sur « Download ».
Le résultat est visible dans n’importe quel navigateur. Le fichier html de résultats peut être téléchargé ici . Il faut l’enregistrer sur son poste avant de l’ouvrir avec un navigateur.
Quelques remarques conclusives
- Ce code est générique, il peut être utilisé avec n’importe quelle liste d’ISSN en entrée (si on ne dispose pas des noms des éditeurs il suffit d’adapter la dernière étape du code)
- Il n’est pas du tout optimisé : il faut 1-2 minutes pour que tout s’affiche, dans le cas de notre exemple. N’hésitez pas à apporter des améliorations !
- La visualisation permet rapidement de se rendre compte de certaines incohérences dans les données : il y en a, elles sont corrigées au fur et à mesure.
B.Bober