
[Lire le billet qui introduit cette série « OpenRefine au service de BACON : quelle évaluation pour les fichiers KBART ? »]
OpenRefine est un outil open source conçu pour manipuler des données dont la qualité nécessite un traitement. Mais il permet bien plus que de nettoyer un fichier tabulé des scories qu’il contient. Comparable à Excel, son principal intérêt est de permettre l’appel à des services web. Il est alors possible, et facile, de comparer le contenu d’un fichier avec une base de référence disposant d’une API.
Ce billet est un accompagnement dans vos premiers pas avec OpenRefine : comment l’installer, charger un fichier, effectuer ses premiers traitements.
Étant donné le nombre de tutoriels déjà disponibles sur cet outil, il sera surtout l’occasion de vous communiquer une bibliographie.
1. Installation
OpenRefine est disponible sous Windows, Mac et Linux. Son installation s’effectue sans difficulté, quel que soit l’environnement sous lequel vous évoluez : il suffit de lancer le fichier d’installation correspondant au vôtre, téléchargeable depuis le site officiel.
Un environnement Java est requis.
Vous noterez, sur la même page, la liste des extensions qu’il est possible d’installer afin, par exemple, de permettre les exports en RDF.
2. Chargement d’un fichier
Après avoir lancé OpenRefine, votre navigateur par défaut offre un nouvel onglet. Vous voyez alors apparaître :
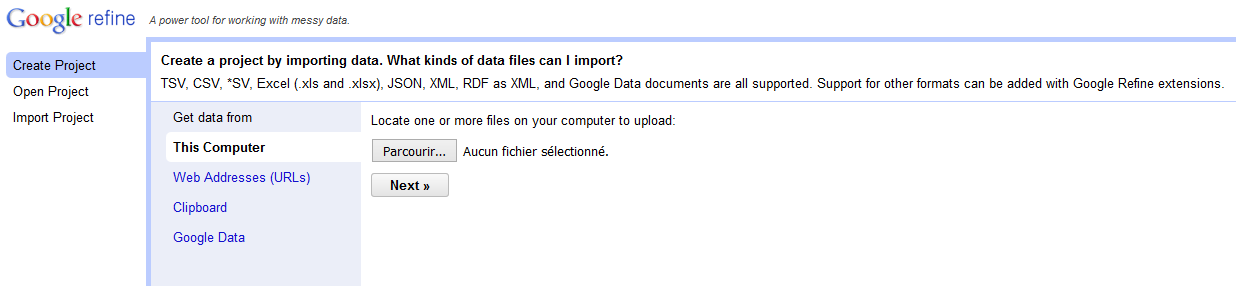
A gauche, trois onglets permettent de créer un projet (onglet actif sur l’illustration), d’ouvrir un projet existant ou d’importer un projet précédemment exporté.
A l’import, OpenRefine accepte de multiples formats. Pour illustrer notre propos, l’exemple utilisé sera celui d’un fichier tabulé (.tsv), ayant pour séparateur la tabulation, encodé en UTF-8. Ce fichier est issu de BACON : « Lavoisier_Global_AllJournals_2016-07-01.txt »
Pour importer un tel fichier après son téléchargement, cliquer sur « Parcourir », sélectionner le fichier dans l’arborescence de l’ordinateur puis cliquer sur « Next ».
Une nouvelle fenêtre apparaît, qui permet de choisir différentes options. Cette copie d’écran reproduit la partie inférieure de l’écran :
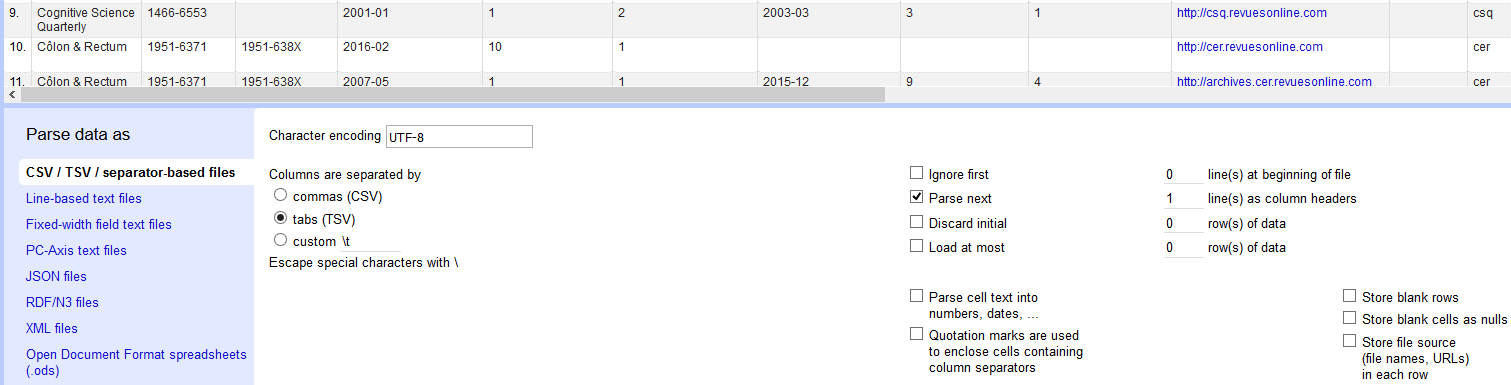
Les options sélectionnées ne correspondent pas à la configuration proposée par défaut, mais aux besoins inhérents au fichier ainsi qu’aux traitements que nous allons opérer.
Il s’agit bien d’un fichier tabulé (fenêtre de gauche à fond bleu), dont le séparateur est la tabulation (« tabs »). La première ligne contient les intitulés de colonnes et doit donc être considérée comme telle (« Parse next »). Il ne nous reste plus qu’à cliquer sur « Create Project ».
3. Présentation de l’interface
Appliquer des traitements sur les données que contient un projet peut s’opérer de deux manières complémentaires : par l’interface graphique ou en appliquant un script. OpenRefine accepte trois langages de programmation différents : GREL (General Refine Expression Language), Jython et Clojure.
Lors de nos traitements, nous utilisons GREL. Avec une subtilité : la fonctionnalité qui permet d’appliquer un script accepte en réalité du Json, qui encapsule l’un des trois langages, dont le GREL.
Par exemple :
{
"op": "core/column-addition",
"description": "Contient obligatoirement P ou F",
"engineConfig": {
"mode": "row-based",
"facets": []
},
"newColumnName": "access_type_format",
"columnInsertIndex": 55,
"baseColumnName": "access_type",
"expression": "grel:if(isNotNull(value.match(/[PF]/)),value,value+' : format incorrect')",
"onError": "set-to-blank"
}
Ce script vérifie le contenu des cellules de l’access_type, cette colonne du fichier KBART qui informe sur le type d’accès pour un titre : payant (« P ») ou gratuit (« F »). Il respecte la syntaxe Json mais, comme vous pouvez le remarquer, la ligne 11, intitulée « expression » et qui comporte l’appel aux fonctions, déclare en prémisse que le contenu de l’expression suit la syntaxe « grel ».
La méthode par script n’est pas la plus évidente à mettre en œuvre lors d’une première utilisation. La prise en main d’OpenRefine gagnera à se faire par l’interface graphique. Mais, très vite, il est nécessaire d’avoir recours à l’un des langages de programmation, nombre de fonctions n’étant pas accessibles par l’interface.
En revanche, pour s’initier au GREL, l’interface est un excellent outil qui permettra d’ailleurs un gain de temps considérable. En effet, plutôt que de coder directement en Json, mieux vaut utiliser l’interface graphique pour renseigner les expressions GREL. Il sera ensuite toujours possible de récupérer, par une extraction de l’historique, les expressions GREL qui apparaîtront alors directement revêtues de leur habit de Json.
Voilà pourquoi les deux méthodes sont complémentaires.
Pour reprendre l’exemple précédent, voici la méthode a priori la plus simple pour parvenir au résultat escompté.
- dans l’interface, sélectionner la flèche correspondant à la colonne sur laquelle mener l’opération. Sélectionner « Edit cells » > « Transform ».
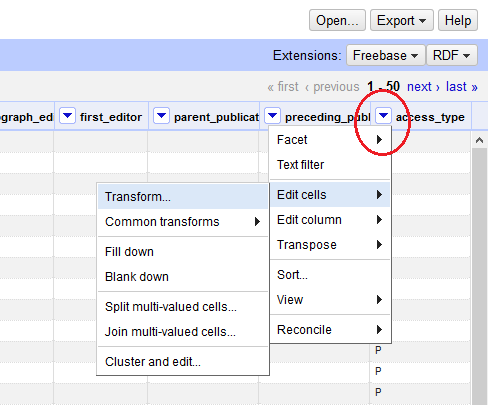
- cette action a pour conséquence l’ouverture d’une nouvelle fenêtre, depuis laquelle nous allons renseigner l’expression correspondant à l’opération que nous voulons mener (2), en GREL (1). Le résultat sur les cellules est directement visible (3).
[Les valeurs « l » (l. 1) et « F » (l.3) ont été modifiées pour les besoins de l’exemple]
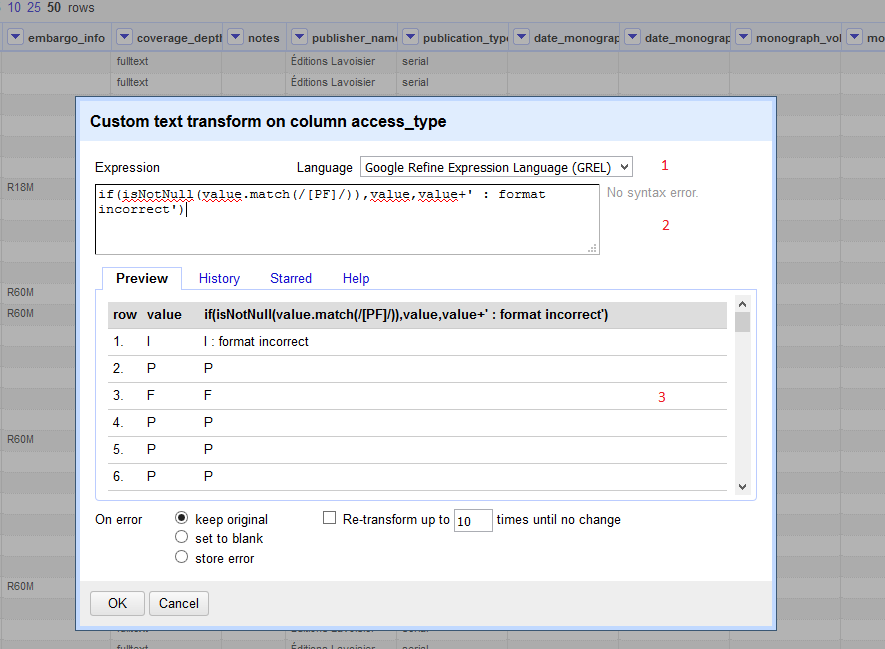
Nous ne nous arrêterons pas dans le détail sur la manière dont l’expression est construite. Ce qui nous importe ici est le résultat obtenu et le moyen de le reproduire facilement en récupérant le script au format Json.
- pour ce faire, après avoir appliqué l’opération en cliquant sur « OK », nous allons sélectionner l’option « Extract » depuis l’historique.
Remarquons que trois actions ont été menées jusqu’à présent sur ce projet : les opérations 1 et 2 correspondent à l’édition des lignes 1 et 3 de la colonne access_type afin de rendre l’exemple plus parlant. La troisième, celle qui nous intéresse réellement, correspond à la vérification du contenu de cette colonne : si l’une des cellules qui la constituent contient une valeur autre que « P » ou « F », alors la valeur initiale doit apparaître, suivie de la mention « format incorrect ». Dans le cas contraire, seule la valeur initiale doit apparaître.
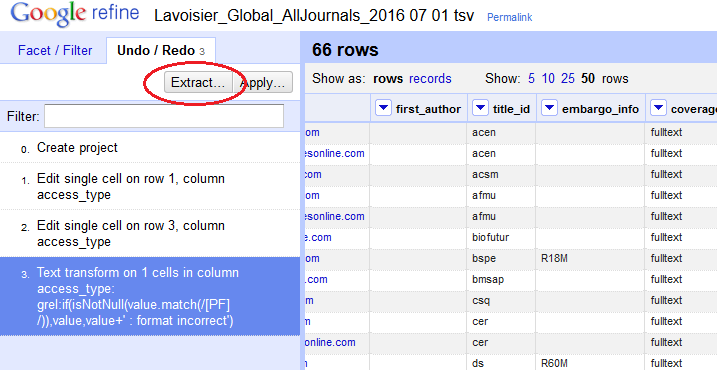
- après avoir cliqué sur « Extract » une nouvelle fenêtre nous permet de sélectionner la partie du code, formaté en Json, qui nous intéresse. Ici, seulement celle qui correspond à la troisième étape, d’ailleurs la seule accessible, l’édition manuelle de contenu ne pouvant être exportée.
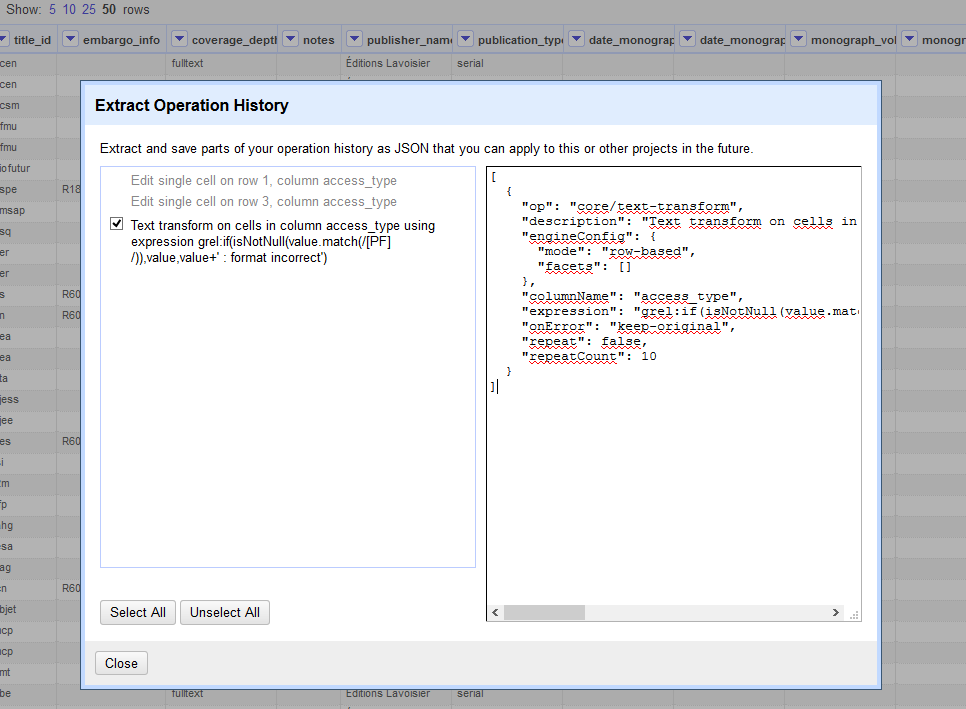
Il est alors facile de copier le code afin de le conserver pour une utilisation ultérieure. Il suffira, sur un nouveau projet, de coller le code correspondant, au format Json, dans la fenêtre accessible en cliquant sur « Apply » dans l’historique puis de valider à l’aide de « Perform Operations »
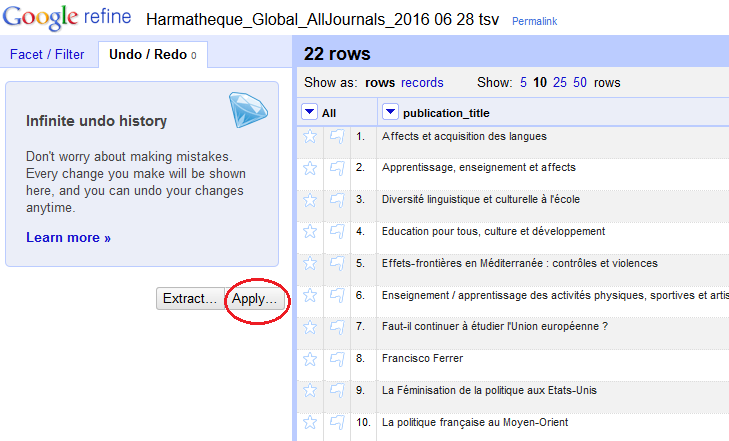
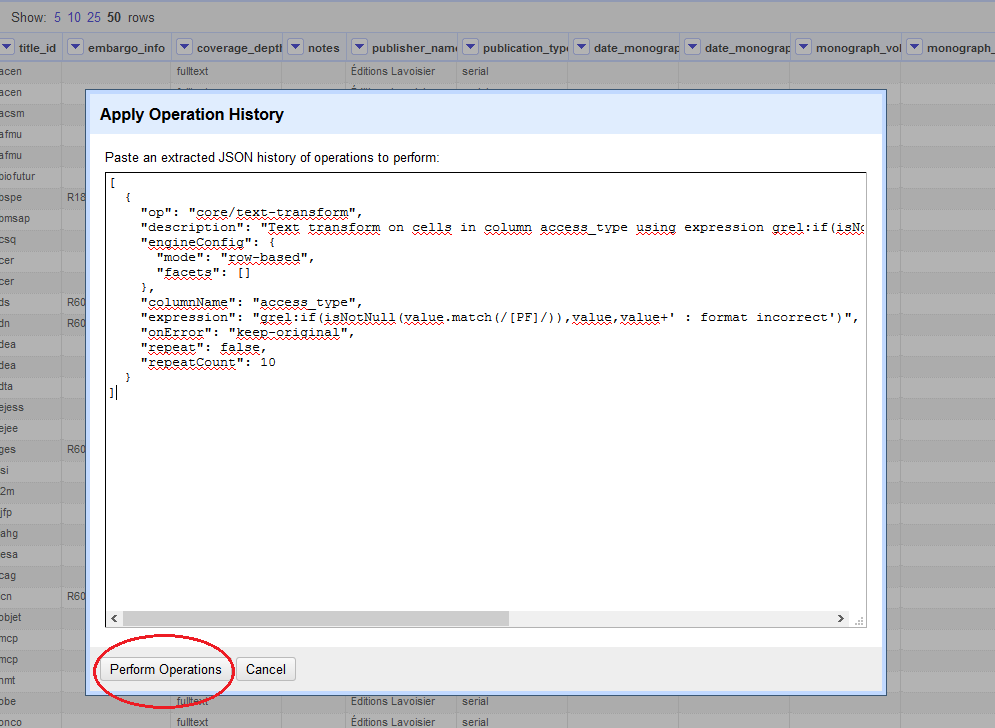
Vous avez peut-être remarqué la présence d’une différence entre le script tel que je vous l’ai présenté en début de ce chapitre et celui qui a été généré par OR et copié tel quel dans la fenêtre « Apply Operation History » ci-dessus.
Il s’agit de la « description » du code. En Json, les commentaires apparaissent dans cette partie, en texte libre pourvu que le texte soit entre guillemets. Pour une meilleure lisibilité et afin d’apporter des éléments plus précis que ceux contenus dans la description générée automatiquement par OpenRefine, son contenu a été modifié dans le script du début de chapitre.
A venir : Dans le prochain billet, nous vous communiquerons les scripts utilisés afin d’évaluer les fichiers KBART.
Bibliographie :
- github officiel : https://github.com/OpenRefine/OpenRefine/wiki. Dont la documentation : https://github.com/OpenRefine/OpenRefine/wiki/Documentation-For-Users.
- page de Bibliopédia consacrée à OpenRefine : http://www.bibliopedia.fr/wiki/OpenRefine.
- le wiki de l’INRA pour prendre en main OpenRefine : http://wiki.inra.fr/wiki/traitementsdocumentaires/Main/OpenRefine.
Cyril Leroy
Ping : OpenRefine au service de BACON : quelle évaluation pour les fichiers KBART ? [1] – Introduction | Punktokomo ;
Ping : OpenRefine : quelques ressources en français | L'Endormitoire