
 Chantiers qualité dans Calames : contexte et objectifs
Chantiers qualité dans Calames : contexte et objectifs
Dans la seconde moitié des années 2010, plusieurs chantiers qualité ont été menés en concertation avec le groupe de travail Calames. Ces opérations reposaient principalement sur des modifications de masse réalisées par l’Abes, avec une simple information communiquée au réseau.
En 2020, dans le contexte particulier du confinement, un chantier qualité ciblant les autorités et leurs liens avec les notices IdRef s’est déroulé sur plusieurs mois. Pour la première fois, les établissements du réseau ont été sollicités pour améliorer ces liens, grâce à l’envoi par l’Abes d’un tableau de diagnostic détaillé.
En 2023, lors de la journée réseau Calames intitulée « Le Voyage des données », ces chantiers qualité ont été évoqués à nouveau. Il a été annoncé qu’ils seraient relancés afin de préparer la migration des données Calames vers un nouvel outil destiné à remplacer l’actuel.
Cette attention à la qualité des données est également essentielle pour anticiper d’éventuelles conversions vers de nouveaux modèles, comme EAD 4 (dont la publication est prévue en 2026) ou RiC (publié fin 2023).
Identifier les chantiers pertinents
En 2024, l’équipe Calames a identifié les chantiers qualité pertinents en procédant au requêtage de la base de production. Deux types de cas ont été privilégiés :
- Des cas repérés dans la base avec une certaine régularité lors d’interventions sur les données ou de traitements de tickets d’assistance
- Des éléments EAD estimés « stratégiques » du fait qu’ils alimentent des index de recherche dans l’interface publique de Calames : ID de composant, cotes, dates, indexation de personne physique, collectivité, famille, lieu géographique, sujet ou langue.
Une trentaine de chantiers qualité potentiels ont ainsi été identifiés et classés en ordre de priorité selon le degré d’importance de l’élément ou de l’attribut EAD concerné dans les index de recherche Calames et du nombre de formes erronées à corriger sur l’ensemble des données publiées dans Calames, les données présentes en base de production, mais non publiées, ayant été systématiquement écartées de l’analyse.
S’aider de l’intelligence artificielle pour modifier les données en masse
Pour réaliser des modifications de masse sur les données, l’Abes utilise deux outils internes : l’un dédié au Sudoc et à IdRef, l’autre à Calames.
Ces outils reposent sur des scripts développés en langage Java, s’appuyant sur l’API standard du DOM W3C. Cette bibliothèque permet de créer, manipuler et analyser des documents XML, en offrant une navigation fine au sein de la structure arborescente des nœuds XML. Grâce à cette technologie, il est possible, en théorie, d’accéder à tout élément ou attribut EAD contenu dans les composants d’un fichier, afin de les modifier de manière ciblée.
L’IA à la rescousse de la qualité des données Calames
La production de ces scripts peut toutefois s’avérer fastidieuse pour des non-informaticiens, notamment selon la complexité des éléments ou attributs EAD à modifier. Afin d’accélérer ce processus et de limiter la sollicitation récurrente des informaticiens, il a été décidé de recourir à un modèle d’intelligence artificielle.
A cette fin, un agent LLM (Large Language Model) a été entraîné pour permettre aux utilisateurs de générer des scripts Java adaptés aux données Calames, sans avoir besoin de connaissances en développement ou en langage de programmation. L’objectif : traduire automatiquement une demande formulée en langage naturel — par exemple, une requête manuscrite décrivant le type de modification souhaitée — en instructions compréhensibles par la machine, tout en respectant la DTD EAD.
Concrètement, un agent LLM est un programme informatique avancé, fondé sur un grand modèle de langage. Il est capable de comprendre et de produire du texte grâce à l’intelligence artificielle. Basé sur un modèle préalablement entraîné, il est ensuite configuré de manière spécifique pour répondre à un usage ciblé — ici, la génération de scripts Java pour le traitement de données XML dans Calames.
Entraînement et configuration des agents LLM
Dans notre cas, les tests ont été menés avec deux agents LLM : l’un basé sur GPT-4-turbo via ChatGPT, l’autre sur Codestral 25.01, accessible via La Plateforme de Mistral AI.
Pour que les agents puissent produire des scripts pertinents, un contexte précis leur a été fourni : normes à respecter (notamment la DTD EAD), bibliothèques Java utilisées, et un échantillon représentatif des données Calames.
La configuration intègre également les spécificités du langage XML, les pièges classiques identifiés lors de l’écriture de scripts, ainsi que des consignes permettant de limiter les erreurs récurrentes.
Construction d’un jeu d’entraînement
En amont, une liste de requêtes de modification courantes a été constituée. Pour chaque demande, un développeur a rédigé le script Java correspondant, servant de référence.
Cette base a ensuite permis d’entraîner l’agent LLM, afin qu’il puisse adapter ses réponses à des formulations en langage naturel, tout en produisant du code exploitable.
Des instructions précises ont également été données sur le format de sortie attendu, la syntaxe à respecter, ainsi que le style de commentaire dans les scripts.
Un nombre conséquent de tests et d’itérations a été nécessaire pour affiner les réponses de l’agent, et le rapprocher au maximum du cahier des charges défini initialement.
Utilisation concrète via Mistral AI
Les tests ont été réalisés avec des agents basés sur GPT-4-turbo via chatGPT et Codestral 25.01 via La Plateforme de Mistral AI.
Pour la configuration, le contexte, les normes et les librairies utilisées ont été fournies aux agents LLM. Un échantillon du type de données à partir duquel il doit travailler a également été fourni. La configuration a dû faire état des particularités du langage et des écueils connus lors de l’écriture de scripts afin de circonscrire les erreurs connues.
Dans le cas de Mistral, l’utilisateur accède à l’agent conversationnel via la page dédiée de “Mistral AI : Le Chat”, où il peut appeler l’agent LLM entraîné par l’Abes. Il lui suffit alors de formuler sa demande comme il le ferait auprès d’un développeur, en langage courant.
Dans l’exemple ci-dessous, l’agent produit un script Java destiné à être utilisé dans l’outil de modification de masse de Calames. Le fichier texte d’entrée n’a pas besoin d’être détaillé dans son contenu ; seule l’indication de la colonne à cibler dans ce fichier est nécessaire pour générer le script adéquat.
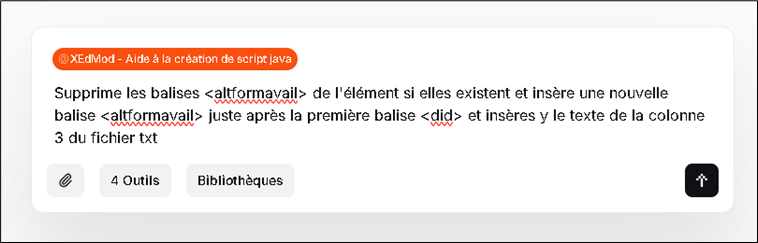
En quelques secondes l’agent LLM génère un nouveau script Java en suivant les instructions. Si l’utilisateur n’est pas satisfait, il peut modifier sa demande plusieurs fois.
Des scripts en Java étant également utilisés pour les modifications de masse côté Sudoc, un agent LLM a été adapté pour produire de la même manière des scripts adaptés à Unimarc.
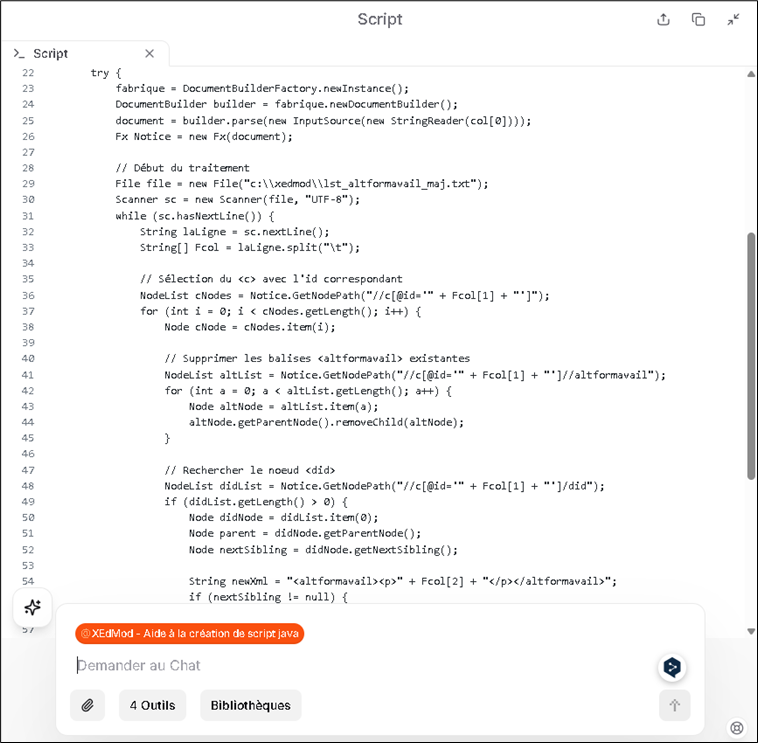
Le résultat généré par l’agent LLM est un script adaptable qui vise à modifier en masse, de manière très précise les données ciblées. Lors de la génération d’un script, l’agent LLM peut énumérer les détails du script qu’il a généré et permettre à un interlocuteur profane de comprendre ce qu’il fait.
Mais l’IA peut se tromper et des itérations sont parfois nécessaires si le script produit provoque des messages d’erreur : dans ce cas, une fois qu’on lui a indiqué l’erreur, l’IA est capable de corriger elle-même son propre script.
Par sécurité, avant toute exécution en base de production, les scripts sont testés sur des cas types en base de formation Calames et le fichier EAD modifié est alors vérifié par un humain dans un comparateur de fichiers XML. La comparaison avec la version avant modification permet de visualiser ce qui a été modifié ou non et si des modifications non voulues ne se sont pas produites.
Comment fonctionnent les scripts en Java ?
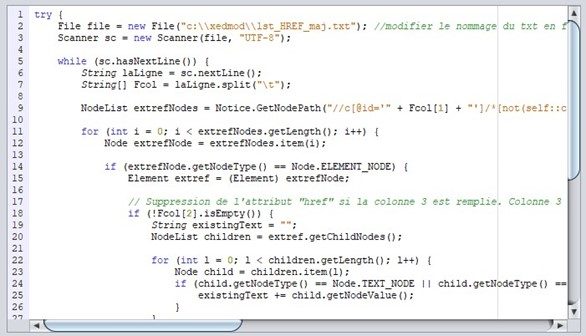
La structure de tous les scripts produits par l’IA est la même : ils débutent par l’identification du composant où se trouve(nt) la ou les données à modifier ; chaque composant EAD ayant un identifiant unique dans Calames, les identifiants des composants concernés sont listés dans la colonne d’un fichier txt appelé par le script :
![]()
Puis les scripts procèdent à des boucles pour isoler le ou les éléments EAD concerné(s) au sein de chaque composant, comme ci-dessous pour un élément <extref> :

Les scripts procèdent, si nécessaire, à la suppression des valeurs à corriger dans un ou plusieurs éléments ciblés. Le cas échéant, de nouvelles valeurs sont générées automatiquement pour les remplacer. Une fois les modifications appliquées à un composant, le script passe au suivant, en bouclant à nouveau sur les éléments à traiter dans ce nouveau composant. Ce processus se répète jusqu’à ce que tous les composants concernés aient été parcourus.
Grâce à ce fonctionnement, des milliers de composants répartis dans des dizaines de fichiers EAD issus d’une même base de données peuvent être traités en quelques minutes par un seul et même script.
Pour sécuriser l’opération, l’outil utilisé par l’Abes pour la modification de masse permet de cibler précisément les fichiers EAD concernés : il suffit d’indiquer leurs clés (identifiants de fichiers). Cela garantit que seuls les fichiers explicitement sélectionnés seront modifiés, évitant ainsi toute intervention involontaire sur des données non concernées.
Identifier précisément la donnée à modifier
Aussi rapide soit-elle, la génération d’un script ne dispense pas de vigilance : le script doit cibler avec précision la donnée à corriger ou à mettre à jour, sans risquer d’altérer d’autres données similaires mais correctes.
Lorsqu’un élément EAD est non répétable, sa présence unique dans un composant garantit que le script agira sur la bonne cible. En revanche, dans la majorité des cas, les éléments concernés sont répétables — autrement dit, plusieurs occurrences du même type d’élément peuvent coexister dans un composant. Il devient alors indispensable de mettre en place des critères de sélection fiables pour que le script n’intervienne que sur l’occurrence à modifier, sans toucher aux autres qui sont déjà conformes ou à jour.
Exemple de ciblage précis : le cas des éléments <unitid>
Prenons un cas concret : un composant contient cinq éléments <unitid>, dont un seul doit être modifié. Il est essentiel que le script identifie précisément celui-ci, sans toucher aux autres.
Si le <unitid> à modifier est le seul à porter l’attribut @type="cote" tandis que les quatre autres ont @type="ancienne_cote", alors l’attribut type suffit à le cibler de manière fiable.
En revanche, si l’élément à modifier est lui aussi un <unitid> de type="ancienne_cote", l’attribut seul ne suffit plus : il faudra alors croiser ce critère avec le contenu textuel de l’élément (ayant une valeur spécifique) pour s’assurer qu’il s’agit bien du bon <unitid>.
Ce genre de vérification conditionne la qualité du script : un ciblage trop large peut entraîner des modifications non souhaitées, tandis qu’un ciblage trop restrictif peut empêcher la modification attendue. D’où l’importance de bien analyser les cas de figure avant d’automatiser.
Plutôt pas assez que trop : les limites du ciblage par valeur
La vérification des valeurs d’attributs et du contenu textuel d’un élément est ce qui garantit la fiabilité du ciblage. Mais cette méthode a aussi ses limites.
En effet, si le contenu textuel contient des caractères parasites — espaces superflus, tabulations, retours à la ligne —, le script peut ne pas reconnaître l’élément comme correspondant à la valeur attendue. Ce problème se pose plus rarement sur les attributs, généralement mieux structurés.
Dans ce cas, l’élément ciblé n’est pas trouvé, et le script passe à l’occurrence suivante, que ce soit dans le même composant ou dans un composant différent, sans effectuer la modification attendue.
Ce type d’imprécision explique pourquoi, à l’issue d’une opération de modification de masse, le nombre de modifications effectivement réalisées peut être légèrement inférieur à celui initialement prévu ou identifié.
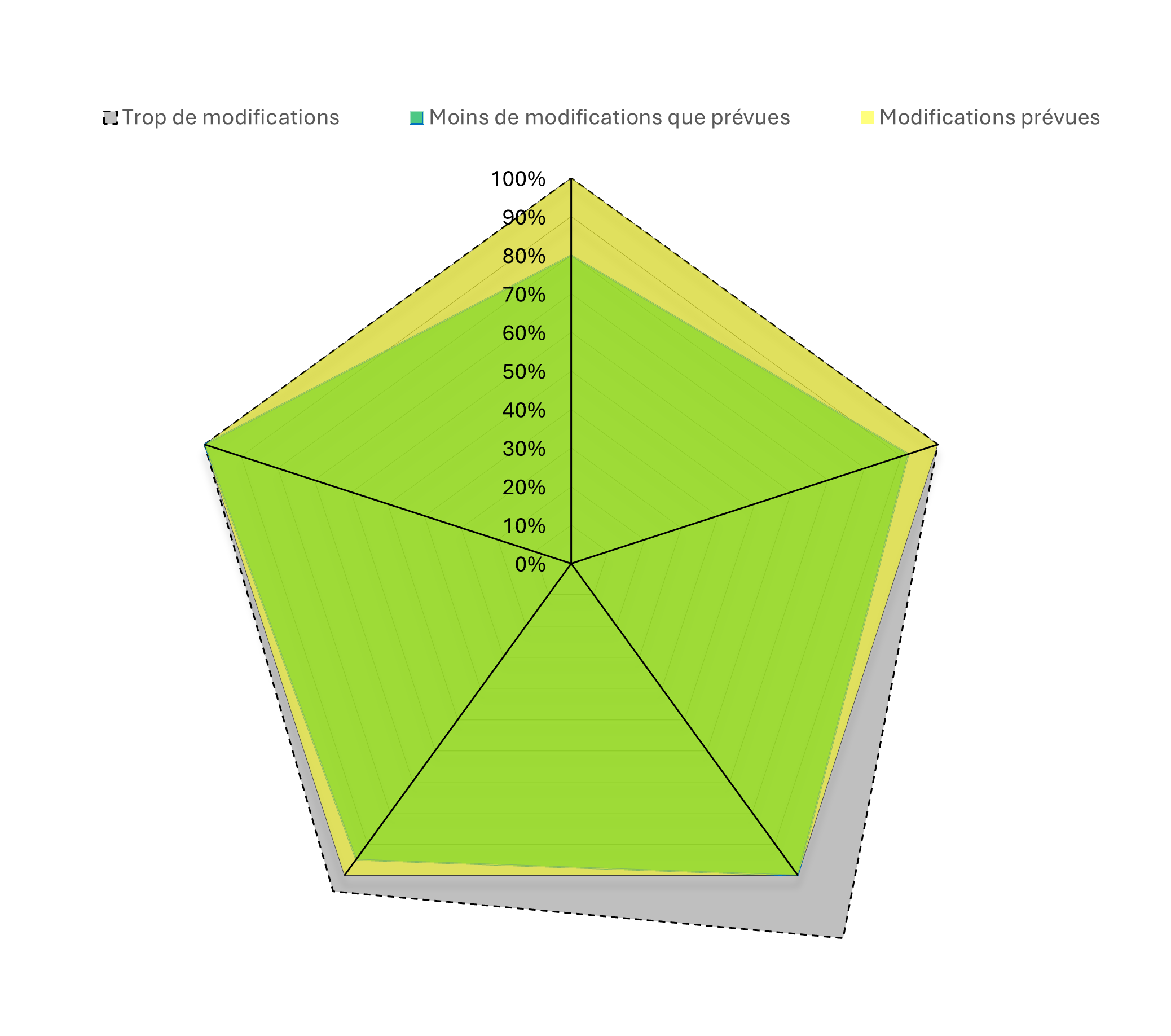
Limites des scripts et enjeux de qualité des données
Entre deux risques — corriger trop largement au point d’introduire de nouvelles erreurs, ou corriger trop peu et laisser passer certaines anomalies — l’Abes choisit résolument la prudence. Mieux vaut que quelques erreurs subsistent plutôt que de risquer d’en créer de nouvelles.
Un fichier EAD est structuré en trois grandes parties :
<eadheader>, qui contient des métadonnées sur le fichier lui-même,
le haut niveau de description,<archdesc>, qui regroupe les informations communes à l’ensemble du contenu,- et enfin le
<dsc>, enfant de<archdesc>, qui contient les composants (unités documentaires décrites).
Les scripts Java évoqués plus haut sont conçus pour intervenir uniquement au niveau des composants, ce qui couvre l’essentiel des données publiées dans Calames. Toutefois, certaines mises à jour peuvent également concerner des données situées en <eadheader> ou en <archdesc>.
Dans ces cas-là, il est nécessaire d’effectuer des requêtes SQL UPDATE directement dans la base. Bien que plus sensibles, ces interventions restent maîtrisées : en cas d’erreur, il est possible de restaurer les fichiers à partir des versions de sauvegarde. Les établissements sont d’ailleurs invités à ne pas intervenir simultanément dans la base lorsque l’Abes procède à des modifications de masse, pour garantir la cohérence des données.
Lorsque des corrections doivent être apportées à la fois dans <archdesc> et dans les composants, il est possible de les regrouper dans un même chantier, mené sur une journée.
Conclusion : une amélioration continue de la qualité
La qualité des données n’est jamais totalement acquise — ni à leur production par les collègues des établissements du réseau Calames, ni après correction par l’Abes. Mais ce sont bien ces efforts progressifs, concertés et itératifs qui permettent de tendre vers un niveau de qualité toujours plus élevé, au service des usagers et des outils de signalement.
D’autres billets sont à suivre sur les chantiers qualité menés entre mars et juillet 2025 dans Calames afin de donner plus de détails pour chaque chantier.
Ping : Les documents iconographiques décrits dans Calames (1) : contours d’une analyse globale - PUNKTOKOMO