
Ce billet, à la suite du précédent, vise à partager via l’explicitation et la traduction les quatre billets co-publiés par les blogs de ROR et CrossRef au sujet de l’alignement (matching). Ce deuxième volet démolit les mythes et introduit la question de l’évaluation des stratégies d’alignement.
Billets originaux : The Myth of Perfect Metadata Matching et How Good Is Your Matching?

Reconnaître les fausses croyances
Le problème avec ces perceptions faussées, c’est qu’elles ne permettent pas d’avoir une idée réaliste de ce qu’on peut attendre d’un processus d’alignement.
Parmi les problèmes qu’elles attirent, se trouvent surtout des attentes démesurées, ou la sous-estimation du temps et du travail nécessaire pour le mener à bien.
Premier espoir déçu : une stratégie doit être 100% correcte
Hélas la perfection n’est pas de ce monde. Bien que ce soit évidemment l’idéal vers lequel on tend, la pratique des alignements nous fait rapidement entrevoir pourquoi ça n’est pas possible. Tout d’abord, parce que lorsqu’on a en entrée des données non structurées, donc des chaînes de caractères, elles ont été produites et pensées par des êtres humains. Divers. Faillibles. Mais aussi dotés, outre d’une imagination sans limite pour les fantaisies orthographiques, d’une capacité d’inférence liée au contexte, qui fait qu’elles rétablissent d’emblée, à partir de chaînes variables, le sens attendu. Pour mener un alignement via des machines, il faut trouver comment expliciter toutes ces opérations mentales de structuration, d’appariement, de développement d’acronymes ou d’abréviations, de distinctions d’homonymes, pour qu’elles puissent être systématisées et reproduites.
Reprenons l’exemple du billet originel qui donne cette liste de données d’entrées :
| 1. « Department of Radiology, St. Mary’s Hospital, London W2 1NY, UK »
2. « Saint Mary’s Hospital, Manchester University NHS Foundation Trust » 3. « St. Mary’s Medical Center, San Francisco, CA » 4. « St Mary’s Hosp., Dublin » 5. « St Mary’s Hospital Imperial College Healthcare NHS Trust » 6. « 聖マリア病院 » |
Parmi ces chaînes de caractères, il va falloir objectiver les critères qui permettent de débrouiller plusieurs situations non triviales !
- Une même organisation peut posséder plusieurs noms (variantes : Saint Mary’s Hospital / St Mary’s hospital / St. Mary’s Hosp.)
- Le nom d’une institution peut être utilisé dans des langues différentes (traduction : la ligne 6 “聖マリア病院” est la traduction en japonais de “St. Mary’s Hospital”)
- Plusieurs organisations sont homonymes, c’est-à-dire ont en commun au moins une partie de leur nom, alors qu’elles sont bien distinctes (il y a des Marie très saintes un peu partout ici)
- La dénomination géographique peut être fonction du contexte, et s’avérer insuffisamment précise au sein d’un jeu de données (parle-t-on de Dublin, la capitale de l’Irlande, de Dublin, Ohio aux Etats-Unis[1] ?)
- Une organisation peut faire partie d’une autre (enchâssement : le St. Mary’s Hospital de Londres appartient à l’Imperial College Healthcare NHS Trust par exemple, et ce savoir est extérieur au jeu de données lui-même)
Méditons sur ce principe jamais démenti : “In real world circumstances, no dataset is fully accurate, complete, or current and certainly not all three.” Que l’on pourrait traduire par « les métadonnées d’entrées avec lesquelles nous travaillons ne sont jamais toutes à la fois correctes, complètes et à jour. » La connaissance de la signification et du contexte de toutes les chaînes de caractères qui composent le set de données n’existe pas : il y aura donc, dans le fatras de notre réalité, toujours des surprises, de l’inattendu, de l’incompréhensible, des ratés.
Deuxième désillusion : c’est toujours une bonne idée d’adapter la stratégie à la spécificité des données d’entrées
Les stratégies d’alignements ne sont donc pas parfaites. C’est donc qu’elles peuvent être améliorées ! Hum… C’est là que réside le second piège. Lorsqu’en parcourant les résultats, on rencontre un alignement erroné ou manquant, la tentation est grande de considérer ce cas un peu comme un bug logiciel, et de vouloir adapter la stratégie pour qu’elle fournisse un résultat plus enthousiasmant. Sur ce cas au moins. Mais sans forcément penser à tous les autres… Or, en réalité, la stratégie d’alignement va toujours naviguer entre deux pôles, précision (precision) et rappel (recall). Que signifient ces deux métriques ?
La précision est la mesure obtenue en divisant le nombre d’alignements corrects obtenus par le nombre total d’alignements réalisés. On peut l’interpréter comme la probabilité qu’un alignement fourni soit correct. Si la précision est faible, alors on se retrouve avec un grand nombre de faux positifs (false positive), c’est-à-dire que beaucoup d’alignements ont été proposés mais ne sont pas justes.
Le rappel est la métrique obtenue en divisant le nombre d’alignement corrects proposés par rapport au nombre d’alignements attendus. C’est donc la probabilité qu’un alignement soit créé. Un faible niveau de rappel signifie qu’on se retrouve avec beaucoup de faux négatifs (false négatives), c’est-à-dire que dans beaucoup de cas, aucun candidat à l’alignement n’a été proposé.
Le schéma ci-dessous résume la situation :
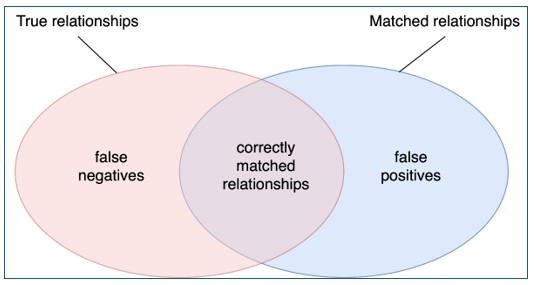
On cherche évidemment à ce que les deux ellipses, les paires correctes (true relationships) et les paires proposées (matched relationships) se recouvrent le plus possible.
Si une stratégie est très stricte, elle aura tendance à passer à côté d’alignements possibles, pour ne proposer que peu de paires, mais majoritairement correctes. On peut songer à l’amélioration en assouplissant des critères, mais alors on se retrouve avec certes davantage de paires, la probabilité que celles-ci soient correcte s’amenuise. Tout alignement est affaire de subtil dosage entre ces deux aspects, ce qui s’avère épineux quand les données d’entrée sont très hétérogènes. Une stratégie qui serait parfaitement adaptée à un cas précis (par exemple, la distinction des homonymes) amène le risque d’être … inadaptée au cas suivant (par exemple, la prise en compte des enchâssements institutionnels).
Troisième ornière : l’alignement sans regard humain, à grande échelle, c’est trop dangereux
Si la précision ne peut jamais être parfaite, n’est-ce pas être conséquent que de s’abstenir d’utiliser des stratégies d’alignement de manière automatique ? Certes. Et pourtant. Dans le domaine des métadonnées décrivant les productions de recherche, il est assez probable que la qualité intrinsèque des données ne soit pas parfaite au départ. Proposer un alignement non supervisé vers des identifiants, est-ce vraiment faire porter un risque substantiel de dégrader la qualité desdites données ? Au contraire, serait-on tenté de répondre. Travailler les métadonnées, les mettre en mouvement et exposer largement le résultat de ce travail, c’est offrir une bonne occasion de regarder la poussière cachée sous le tapis, plus ou moins consciemment et depuis plus ou moins longtemps. Cela nécessite de prévoir des circuits de recueil d’information (feedback) et d’amélioration des données.[2] Enfin, les bonnes pratiques consistent évidemment à sourcer et signaler les alignements créés sans supervision : ainsi, les personnes qui ré-utilisent ces données savent à quoi s’en tenir, et peuvent toujours choisir de ne pas prendre en considération ce qu’elles n’estiment pas assez digne de confiance.
Quatrième erreur : on ne peut évaluer le résultat qu’au doigt mouillé
Tant de limites s’imposent à nous : les données sont hétérogènes au sein d’un jeu de données, et d’un jeu à un autre. Les cas que nous pensons pouvoir traiter correctement sont-ils majoritaires ? N’en avons-nous pas oublié d’autres ? Enfin, nous voilà devant un questionnement parfaitement kantien : Que devons-nous faire ? Et que nous est-il permis d’espérer ?[3]
Il est possible et souhaitable d’évaluer une stratégie d’alignement. On peut distinguer 4 étapes majeures :
- Préparer un échantillon représentatif des données d’entrée, sur lequel on assigne manuellement le résultat attendu de l’opération
- Faire jouer la stratégie d’alignement sur tout le corpus des données d’entrée
- Comparer les résultats obtenus avec les résultats attendus
- Documenter ces résultats à l’aide de métriques.
La constitution d’un échantillon est donc le point de départ. On le souhaite robuste (donc d’une taille acceptable, qui dépend de celle du corpus total) et crédible (issu des vraies données telles qu’elles se présentent en entrée.)
Les métriques vont nous permettre de résumer les résultats de l’évaluation de manière chiffrée : cela permet d’estimer la pertinence de notre stratégie d’alignement, et surtout de pouvoir comparer plusieurs stratégies entre elles. Les métriques, pour donner une image fidèle, doivent pouvoir se combiner. Nous allons voir pourquoi.
La première métrique que l’on peut utiliser, c’est l’exactitude (accuracy), c’est-à-dire la proximité des résultats avec les valeurs correctes. Mais elle ne suffira jamais seule, car comme nous allons le voir à partir du tableau ci-dessous, elle a le tort de noyer le poisson.
Si l’on veut comparer les stratégies 1 et 2 à partir des trois cas du tableau, on se rend compte qu’elles partagent la même métrique d’exactitude : 0,67. En effet, sur les trois cas proposés, chaque stratégie opte pour le bon résultat deux fois sur trois. Mais l’exactitude manque de nuances. Nous avons vu plus tôt que les notions de précision et de rappel permettent d’illustrer plus finement le comportement d’une stratégie. Dans le cas ci-dessus, la stratégie 1 a un taux de rappel (0,5) identique à la stratégie 2, mais elles diffèrent quant à la précision : la stratégie 2 a une métrique de précision de 1,0 (à chaque fois qu’une paire a été proposée, elle est correcte) alors que la stratégie 1 n’a une précision que de 0,5 (la moitié de ses propositions sont justes).
On peut enfin combiner précision et rappel dans une métrique qu’on appelle F-mesure (F-score). Le but est d’évaluer les prédictions pertinentes (bonne précision) en suffisamment grand nombre (bon rappel) sur les données d’entrée. Tout comme la précision et le rappel, la F-mesure varie de 0 (plus mauvaise valeur) à 1 (meilleure valeur possible).[4] Elle peut pondérer le rappel et la précision soit à égalité (F1), soit en donnant prééminence à l’un (F0.5 valorise la précision, alors que F2 valorise le rappel).
À l’échelle d’un jeu de données complet, on suppose donc que la stratégie 1 produira davantage de faux positifs, et la stratégie 2 davantage de faux négatifs. C’est le cas d’usage qui décidera de l’orientation souhaitable. Par exemple, si l’on ne dispose que de peu de temps humain disponible, on peut s’orienter vers le choix de la fiabilité. Au contraire, si l’alignement est conçu comme une proposition à valider ou invalider par une personne, il peut apparaître plus avisé d’avoir un peu de bruit que du silence.
Lectrices, lecteurs, êtes-vous curieux de la manière dont on procède à l’Abes ? Le troisième et dernier billet de cette série est pour vous !
Carole Melzac
Service Autorités et Référentiels
Abes
[1] Dublin est un nom d’une bonne vingtaine des villes dispersées dans plusieurs pays, comme en atteste la page d’homonymie de Wikipédia https://en.wikipedia.org/wiki/Dublin_(disambiguation)
[2] C’est exactement ce que fait ROR avec le formulaire de proposition d’amélioration des données ouvert à toutes et à tous. Par ailleurs, on peut citer un parangon du genre, WorksMagnet , outil développé par le SIES du MESR pour identifier les erreurs d’alignements de structures vers le ROR dans les données d’OpenAlex. Pour en savoir plus, voir le Poster réalisé par l’Université de Lorraine et le MESR
[3] Quant à « Que pouvons-nous connaître ? », si vous arrivez au bout de cette série de billets, considérons que vous en saurez assez long sur ce que sont les alignements pour briller au prochain cocktail des Journées Abes.
Ping : Anatomie des alignements, épisode 1/3 - PUNKTOKOMO
Ping : Anatomie des alignements à l'Abes (ou métaphore des chaussettes), épisode 3/3 - PUNKTOKOMO