
Ce billet est le premier d’une trilogie consacrée au projet dit Sudoc21. Il revient sur les enjeux de la modélisation des données, et sur la manière dont l’équipe en charge du projet s’y est confrontée.
-
- Nom de code Sudoc21
- Les données en diptyque
- Retours sur l’exploration des solutions informatiques (billet technique)
Flash-back
Les JABES 2019, une présentation en plénière sur l’avenir du Sudoc, la refonte du SI de l’Abes, enthousiasme et anxiété de venir dire où nous voulions aller. Depuis ? Ce que nous ne pouvions pas prévoir : le monde mis sens dessus dessous les mois suivants, où le sens de la mesure allait s’inverser – jamais assez loin des autres, toujours trop proche de chez soi. Ce que nous pouvions encore moins imaginer : que Stéphane Rey, responsable informatique du projet, meure brutalement en avril 2020. Et après. Et pourtant. Et malgré. Nous voici au bout de ce projet de deux années, nom de code Sudoc21. Vingt-et-un comme XXIème siècle davantage que 2021, si c’est d’échéance qu’il s’agit. Car au risque de vous décevoir, l’irruption du nouveau système ne sera pas immédiate. Mais au moins avons-nous pu prendre le temps, dans un travail très étroit entre bibliothécaires et informaticiens, de poser correctement les questions pour mesurer le chemin qui nous reste à parcourir.
Une moisson d’idées
Une étude de cadrage, assortie d’une étude dite SCAN évaluant le paysage, avaient été produites en interne courant 2018. Le projet Sudoc21 a permis de conduire une veille particulièrement fournie, autant au niveau national qu’international : auprès de la BnF (projet Noemi), d’Electre (outil Calipse), de l’INA (projet lac de données), de Swissbib, d’OCLC Research (projet Passages) mais encore via les communautés ELAG, SWIB, Code4lib, ou encore LD4P.
La problématique
Deux axes complémentaires permettent de poser le problème auquel fait face l’Abes :
- le système d’information (SI) est éclaté, construit par nécessité en constellation autour d’un socle (CBS, le Sudoc) que nous ne savons ou ne pouvons pas faire évoluer suffisamment, et où les synchronisations entre les bases et les applications deviennent lourdes et difficile à maintenir.
- des métadonnées bibliographiques conservées « en silos » dans des formats différents (MARC/TEF/KBART/RDF/EAD) alors qu’elles décrivent toutes des ressources auxquelles les bibliothèques de nos réseaux donnent accès et sont souvent complémentaires.
Avec pour conséquence l’impossibilité de répondre à des questions d’apparence simple. Par exemple :
- Identifier directement, pour l’édition particulière d’un ouvrage (=manifestation), les établissements où un exemplaire est disponible pour le PEB
- Lister toutes les publications (=œuvres) d’une personne en tant qu’affiliée à une institution donnée afin de savoir sur quels sujets elle a travaillé
- Repérer dans une bibliothèque donnée tous les ouvrages (=manifestations) éditées par tel éditeur afin de compléter une collection d’autres titres de cet éditeur
- Connaître toutes les bibliothèques qui ont accès à un certain bouquet de documentation électronique
La méthode de travail utilisée (SCRUM) nous a amenés à définir ce qu’on appelle la « vision » :
« Mettre à disposition de l’Abes et des établissements de ses réseaux un système permettant l’ingestion, le traitement, le stockage et la fourniture de données bibliographiques ; de manière unifiée dans un environnement technique ouvert, adaptable, évolutif donc maîtrisable par l’Abes et en s’appuyant sur l’exhaustivité des données utiles au métier, structurées selon un modèle de données unique compatible avec IFLA-LRM. »
La piste du « pot commun »
Pour sortir de l’ornière des formats, il faut revenir au soubassement : le modèle de données. La longue mutation des métadonnées que l’on appelle la « transition bibliographique » et qui nous pousse à les rendre ouvertes, visibles, liées, possède depuis 2017 un cadre international validé, IFLA-LRM (Library Reference Model) qui fusionne les modèles de type FRBR, en mettant l’utilisateur au centre. Ce cadre fonctionne avec une logique très simple : définir des entités, et les relations entre elles. Il a le bon goût d’être sobre et extensible, alors nous nous en sommes emparés.
Nous avons décortiqué les métadonnées telles qu’on les voit habituellement pour aboutir à ça :
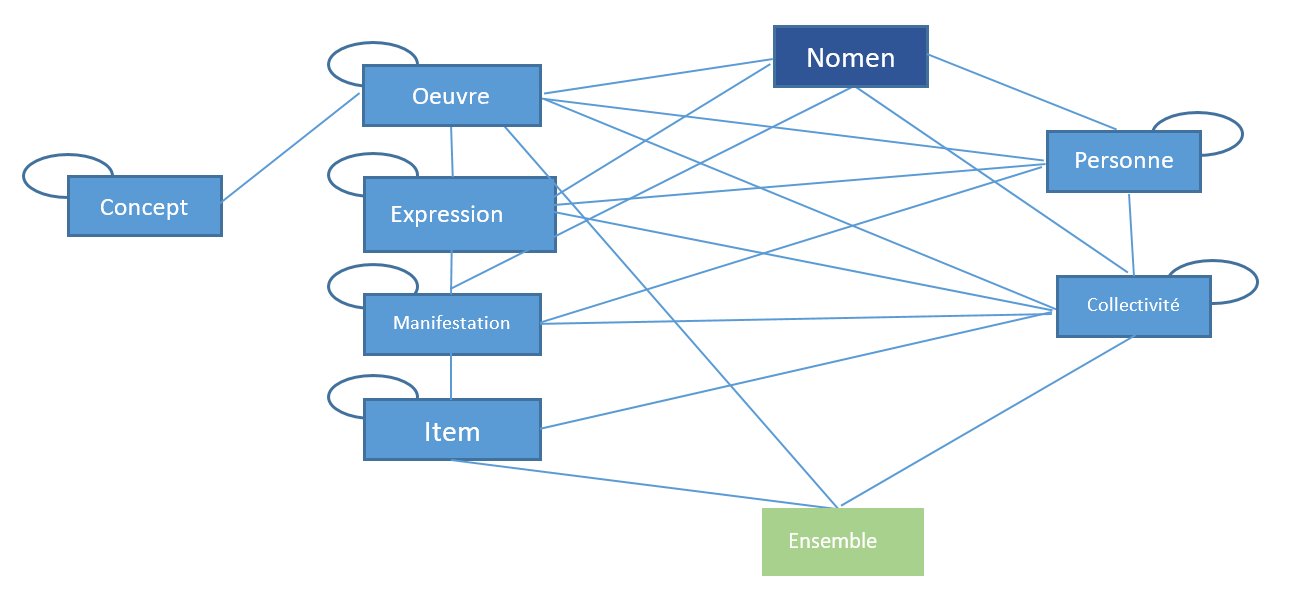
Comment ? Par la grâce de l’XSLT, langage de transformation fonctionnel qui permet de manipuler un document XML. Car le point commun du MARC, du RDF, du TEF, et du KBART est que ces formats professionnels peuvent facilement être encodés en XML à l’aide de balises. Au sein des XSLT, nous avons encodé des règles (propres à chaque format de départ) pour reconnaître les entités à forger et leurs relations. En démembrant les formats natifs, nous avons constitué une sorte de répertoire d’entités et de relations, décrit avec un vocabulaire interne ; mais cette étape de modélisation n’est qu’un premier pas. A partir de ce « pivot exprimé en XML », nous avons pu reconstituer des données structurées en fonction de leur réservoir de destination, les bases de données que nous souhaitions mettre à l’épreuve.
Pourquoi ? Pour faire le lien entre des informations qui aujourd’hui s’ignorent. Faute de trouver leur place dans l’Unimarc du Sudoc, les descriptifs des offres commerciales des éditeurs (les « bouquets » de revues ou de livres électroniques) sont stockés en KBART dans BACON, et les métadonnées précises d’affiliation des articles issus des achats ISTEX sont stockées en RDF dans des bases internes. Les métadonnées en MARC et en RDF peuvent certes s’appuyer sur un référentiel commun (IdRef) ; mais pas celles en KBART. En mettant à plat toutes les informations et en les chargeant au même endroit, on peut enfin les croiser sans être entravés par leur structure propre ou par la difficulté de faire communiquer des bases distinctes.
Ce billet dédié vous en dira davantage sur la modélisation et le processus de transformation des données.
Travaux pratiques
La forme que devait prendre le projet était donnée au départ : trois « preuves de concept ». Autrement trois tentatives, trois axes d’expérimentation, au cours desquels nous allions pouvoir tester des logiques, installer des outils, imaginer des fonctionnements. Tout cela toujours simplement esquissé, temporaire, sans pouvoir tirer de conclusions mais pour conforter des intuitions. Les trois axes sur lesquels nous avons travaillé successivement sont les suivants :
- Le graphe de propriété. Ce modèle de stockage permet de pallier un manque du RDF qui avait été constaté au cours des travaux de modélisation du Hub de métadonnées en ajoutant des propriétés directement sur les relations. Nous l’avons exploré au moyen de l’outil NEO4J.
- Une architecture de base de données relationnelle « classique » articulée avec du graphe classique, que nous avons mise en œuvre dans le Système de gestion de base de données Oracle.
- Les bases RDF de nouvelle génération, acceptant la syntaxe RDF* (une forme de réification proche du graphe de propriété) et le langage de contraintes SHACL, recommandation récente du W3C . Nous avons testé à ce titre les outils GraphDB et Stardog.
Ce billet technique vous en dira davantage sur chacune des implémentations techniques si le cœur vous en dit.
Pour chaque choix technique de stockage, il a fallu « fabriquer » des données conformes à l’attendu de la base. L’avantage d’avoir décortiqué les entités et les relations à l’étape du « pivot exprimé en XML » est que cette étape n’exigeait plus de travail de modélisation, mais consistait plutôt en du formatage technique. Une fois les données chargées, il est devenu possible de lancer des requêtes, dans le langage propre de la base choisie, pour explorer les données.
Zones d’ombres
Il était entendu d’emblée que chaque piste explorée ne pouvait à elle seule constituer une réponse à la problématique initiale. Il ne s’agissait pas d’essayer des candidats interchangeables au remplacement pur et simple du système existant. La notion de « preuve de concept » a évidemment ses limites, et les circonstances n’ont pas été de notre côté. Il reste encore de nombreuses terra incognita qui devront être arpentées avant qu’un nouveau système ne voie le jour.
La première concerne le passage à l’échelle. Au cours du projet Sudoc21, nous avons travaillé avec un échantillon représentatif des métadonnées gérées à l’Abes : 100 000 notices MARC avec leurs exemplaires, 14 thèses en TEF, 2 millions de triplets RDF issus des corpus ISTEX et une poignée de fichiers KBART. Le format EAD n’a pas été traité, faute de temps. L’échantillon nous a permis d’éprouver les mécanismes de transformation de données, de se confronter à divers cas de modélisation, et d’avoir une base construisant des ponts entre chacun de ces quatre formats natifs. Mais pour prendre la mesure de la gigantesque masse de données qu’il va falloir réunir et héberger : cela représente moins de 1%.
Par ailleurs, l’une des caractéristiques centrales des réseaux Abes, assez peu partagée à l’étranger, est le catalogage commun centralisé. Cela veut dire que le cœur du système doit être pensé pour supporter et organiser de manière fluide l’interaction constante et multiple avec des utilisateurs professionnels qui se comptent en milliers. Pour faire un choix technique, il faudra donc à la fois s’assurer de la robustesse de la base en permettant des accès concurrents en écriture, et de la traçabilité des modifications.
Enfin, comment un système central basé sur un nouveau modèle, s’organise-t-il pour continuer à échanger efficacement et sans perte de données avec des établissements ?
Il reste donc de nombreuses étapes sur le chemin. Certaines sont techniques et pourront être instruites à l’Abes dans les mois, les années à venir. Mais la majorité demandent une concertation avec les établissements, une implication de leur part pour que le nouveau système, en embrassant tout le paysage des métadonnées utiles aux bibliothèques des réseaux de l’Abes, soit synonyme d’un meilleur service et de plus de facilité de gestion au quotidien.
Encore merci…
… aux collègues de l’Abes qui ont éclairé pour nous certains recoins de notre système interne et qui ont formé même à distance le public attentif des revues d’itération, aux collègues français et étrangers qui nous ont présenté ce qu’ils avaient réalisé chez eux et accepté de répondre à nos si nombreuses questions, aux équipes techniques des outils testés que nous avons sollicitées. Merci à Stéphane pour tout ce qu’il a commencé, et que nous espérons avoir dignement poursuivi.
Carole Melzac, responsable de projet Sudoc21, Abes
Pour aller plus loin
- Le rapport final du projet présenté au Conseil Scientifique de l’Abes en mars 2021.
Ping : Les données en diptyque : le noyau de la cerise ou la culture du pivot [2-1] - PUNKTOKOMO
Ping : Les données en diptyque : exercice d'apagogie négative [2-2] - PUNKTOKOMO
Ping : Projet Sudoc21 : retours sur l'exploration des solutions informatiques - PUNKTOKOMO
Ping : Veille 2021 – T3 – logiciels libres en bibliothèque, pratiques et actualité - BibLibre - Services et logiciels libres pour votre bibliothèque - SIGB Koha, portail Bokeh, numérique, gestion