
Dans ce dernier billet consacré au projet Sudoc21, sont abordées les solutions informatiques choisies pour tester l’implémentation du modèle de données (format pivot) conçu par les experts de la modélisation bibliographique.
- Nom de code Sudoc21
- Les données en diptyque
- Retours sur l’exploration des solutions informatiques
A partir des différentes solutions logicielles permettant de stocker, interroger et mettre à jour les données structurées selon le format pivot, il s’agissait d’évaluer l’aptitude à traduire en terme de système d’information les différents cas d’usages, et notamment d’évaluer leur complexité technique et leur facilité d’implémentation. De manière générale, le volet « expérimentation des solutions informatiques » a constitué un espace d’échanges et de réflexion entre les membres de l’équipe Sudoc21, indépendamment du domaine de compétences de chacun, ce qui a renforcé la diffusion et le partage d’expertises.
Un projet tourné vers l’avenir
L’équipe informatique du projet Sudoc21 a conservé à l’esprit le fait que le système d’information va être amené à gérer des volumes de plus en plus conséquents : si, en l’état actuel, l’éclatement des données Sudoc en entités s’évalue en milliards, l’objectif est d’atteindre une granularité plus fine encore, comme en témoigne le « en deçà » (ie. chapitres, articles, numéros et volumes) évoqué dans le précédent billet Punktokomo à ce sujet : Les données en diptyque : exercice d’apagogie négative:
“Ce modèle a mis en exergue l’importance de la notion de “granularité” : en deçà, granularité de description documentaire – livres et revues, mais aussi leurs parties composantes -chapitres, articles, numéros et volumes”
Il s’agissait également de tenir compte des assouplissements à prévoir lors de la conception et de l’évolution des schémas de données.
Pour prendre en charge ces contraintes, l’équipe a envisagé, en complément des solutions relationnelles classiques, d’autres solutions de stockage et d’interrogation, qui intègrent des mécanismes plus flexibles. Il existe en effet différentes possibilités techniques permettant :
- soit d’«éclater» des données dans une granularité très fine (« atomique ») – chaque instance pouvant avoir des relations différentes – et de les lier entre elles
- soit d’obtenir un compromis entre de la donnée « tabulée » – classique, relationnelle – et de la donnée « orientée » – composite et faiblement structurée- qui bénéficie peu ou pas des avantages d’un stockage en tables
Dans le cadre du projet Sudoc21, les explorations techniques ont donc été réalisées selon trois approches : une approche relationnelle classique, une approche « graphe » et une approche « mixte »
1 – approche relationnelle
ORACLE (RDBMS)
Les bases de données relationnelles de type Oracle apportent des avantages certains dans de nombreux cas d’usages, notamment en termes de performances. Il s’agit d’outils robustes, bien établis, connus et maîtrisés par les développeurs, les devops et le service en charge de l’architecture.
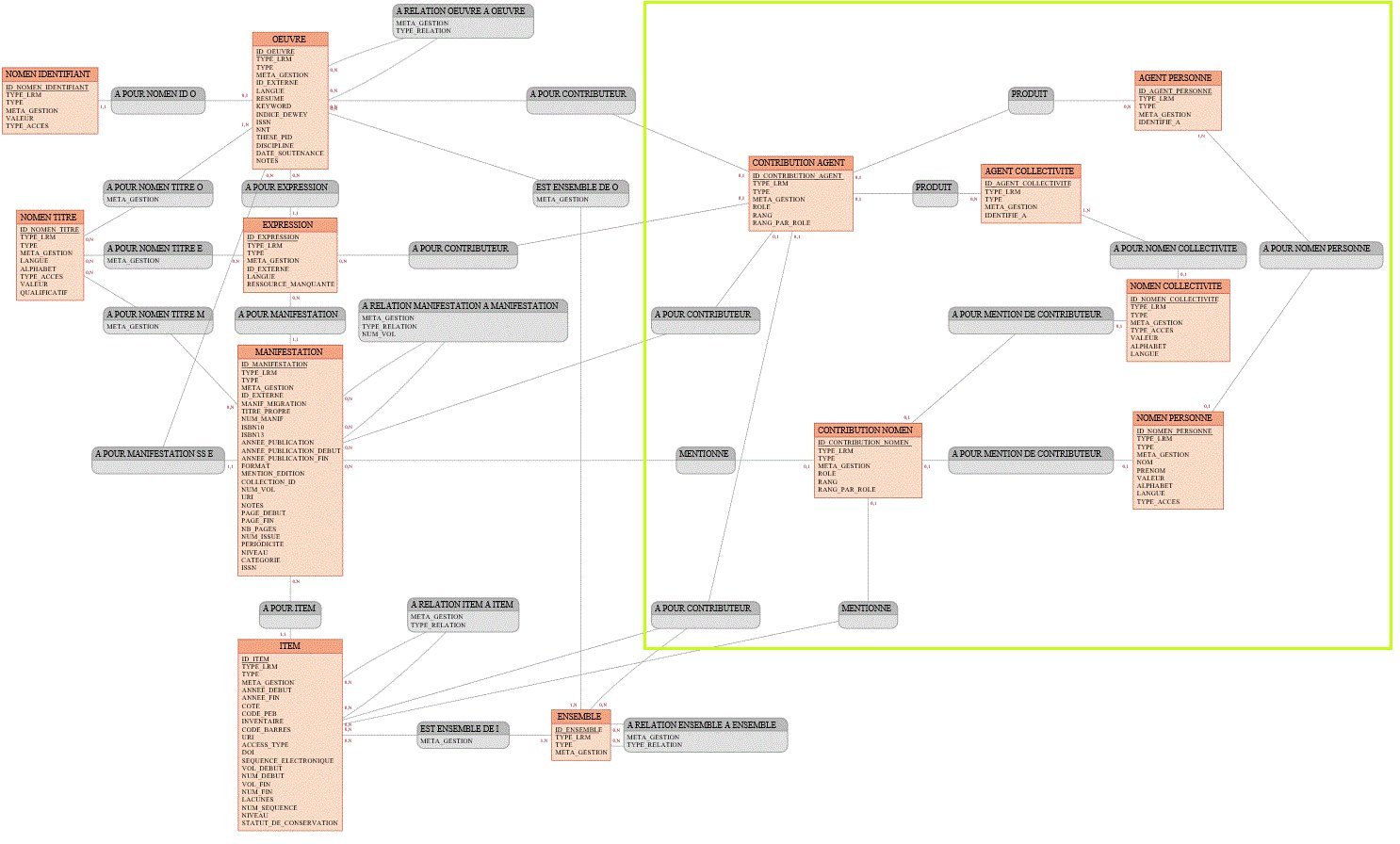
En revanche, si un modèle de données strict de base relationnelle apporte des avantages, notamment une gestion intégrée des contraintes et le fait d’être sûr que les données présentes respectent le modèle défini, celui-ci comporte des difficultés supplémentaires par rapport à d’autres types de stockage : certaines notions du modèle – de type « affiliations« – sont assez peu lisibles lorsqu’on les implémente dans une solution purement relationnelle. D’autres notions – de type « ensembles », « traçage »- nécessitent des jointures entre les tables et/ou impliquent la présence dans les colonnes de nombreuses valeurs « nulles » , ce qui rend les requêtes complexes à écrire sur des entités LRMisées. D’autre part, corriger ou étendre le modèle nécessite la modification du schéma de la base de données, ce qui peut s’avérer bien plus complexe que sur un stockage orienté graphe.
{kind=link}
Une réflexion existe également sur la définition des tables en tant que données elles-mêmes (solutions regroupées sous le nom de modèle «Entité Attribut Valeur», ce qui implique le «déplacement» du schéma relationnel classique (colonnes) au niveau des données (lignes) : la métadonnée est alors gérée de manière explicite et non plus par les mécanismes internes de la base.
Cela ne diminue pas forcément la complexité, et une implémentation naïve présenterait un risque de faibles performances. On remarque dans l’article Wikipedia à ce sujet qui confirme les deux autres pistes décrites dans ce billet en proposant de :
« passer globalement à un stockage « universel » optimisé « graphe » avec RDF qui propose une solution pour exprimer le schéma ou bien à des champs typés XML/JSON pour gérer une information moins rigide (type de données qui présentent également avantages et inconvénients) »
2 – approche graphe de propriétés / RDF / RDF*
Plusieurs outils proposent un éclatement atomique des données, selon des implémentations variables : column store pour Virtuoso ; structure mémoire de type chaînée pour Neo4j ; arbre de fusion basé sur les logs pour Stardog ou Dgraph, outil open source disposant d’une large communauté d’utilisateurs et offrant une solution techniquement proche mais qui n’a pas été évaluée dans le cadre du projet.
Les outils testés dans le cadre du projet Sudoc21 ont été conçus pour permettre l’interrogation de volumes importants de données. Les cas d’usages le plus souvent mis en avant sont la fouille et l’analyse de données et la recherche de fraude. Oracle Property Graph, par exemple, vise quasiment uniquement l’interrogation, le graphe étant monté en mémoire et les requêtes devant être compilées. Précisons que cet outil n’a pas pour but de gérer un flux de données entrantes.
Si les requêtes de type « graphes » sont relativement intuitives – en ce qu’elles permettent à des personnes non spécialistes de prendre en main le système plus facilement qu’avec des requêtes SQL, elles peuvent devenir complexes selon le modèle de données (par exemple pour un grand nombre de tables avec des cardinalités -n, m). De plus, les communautés d’utilisateurs sont plus ou moins réactives.
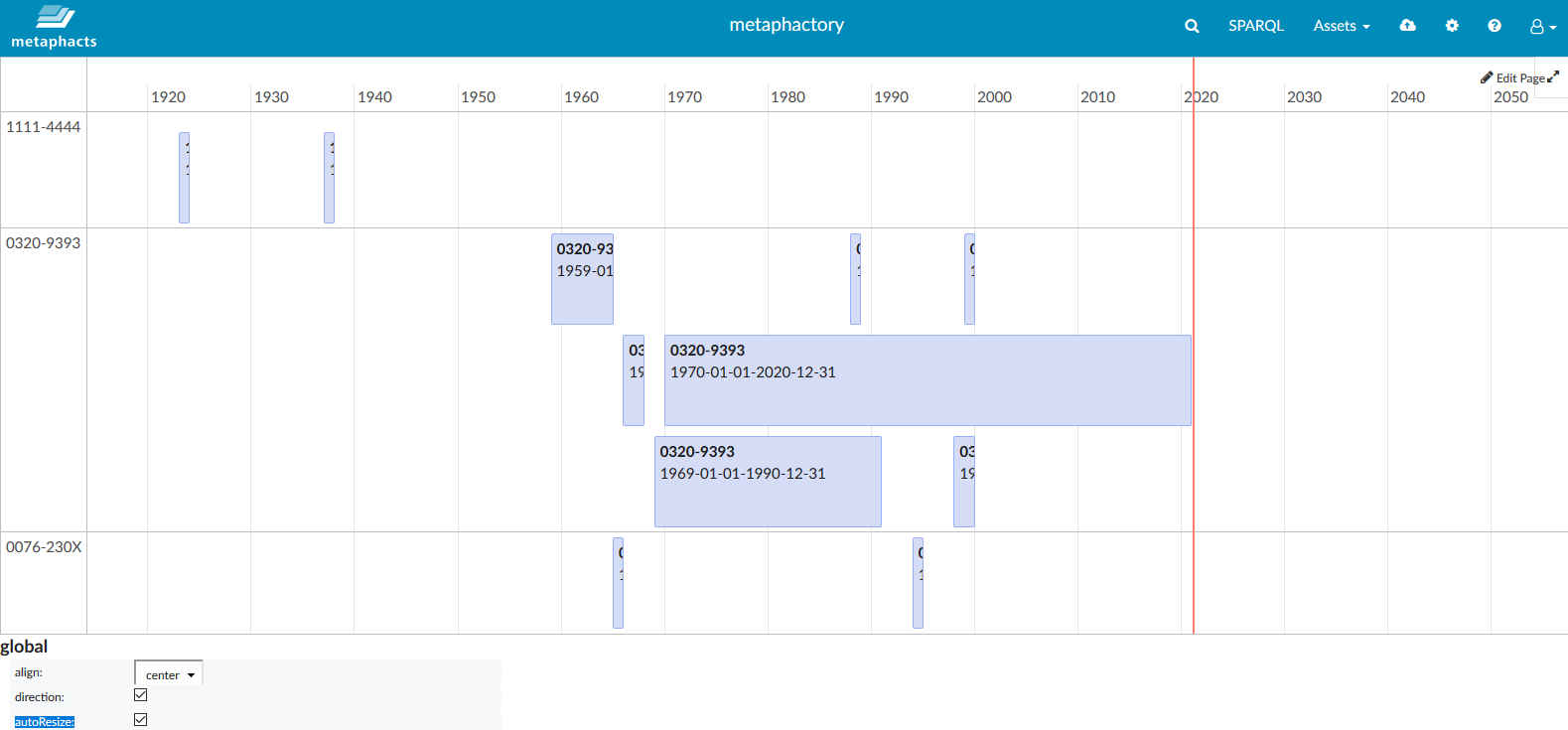
Les bases de type « graphes », telles NEO4J ou Stardog, disposent d’interfaces conviviales, ce qui permet une visualisation intuitive des données et facilite la recherche et l’exploration. En dehors de NEO4J, les bases reposant sur RDF/RDF* proposent de facto le standard d’interrogation SPARQL. Il est possible d’y accoler des outils supplémentaires selon une approche low code (peu de code) qui n’exige pas d’expertise en développement informatique, comme, par exemple, Metaphactory, qui propose une couche supérieure pour simplifier la recherche et l’édition, une API REST et des composants visuels variés (timeline, tableaux, graphiques)
Précisons que d’autres langages, comme SHACL par exemple, existent dans l’univers des graphes RDF et permettent la gestion des contraintes, même si leur implémentation reste souvent partielle. Enfin, même s’il s’agit d’une problématique complexe techniquement, les bases de type « graphes » facilitent la gestion de la provenance et le versioning, de manière très fine en terme de granularité.
Focus sur trois outils
NEO4J (Property Graph, Cypher)
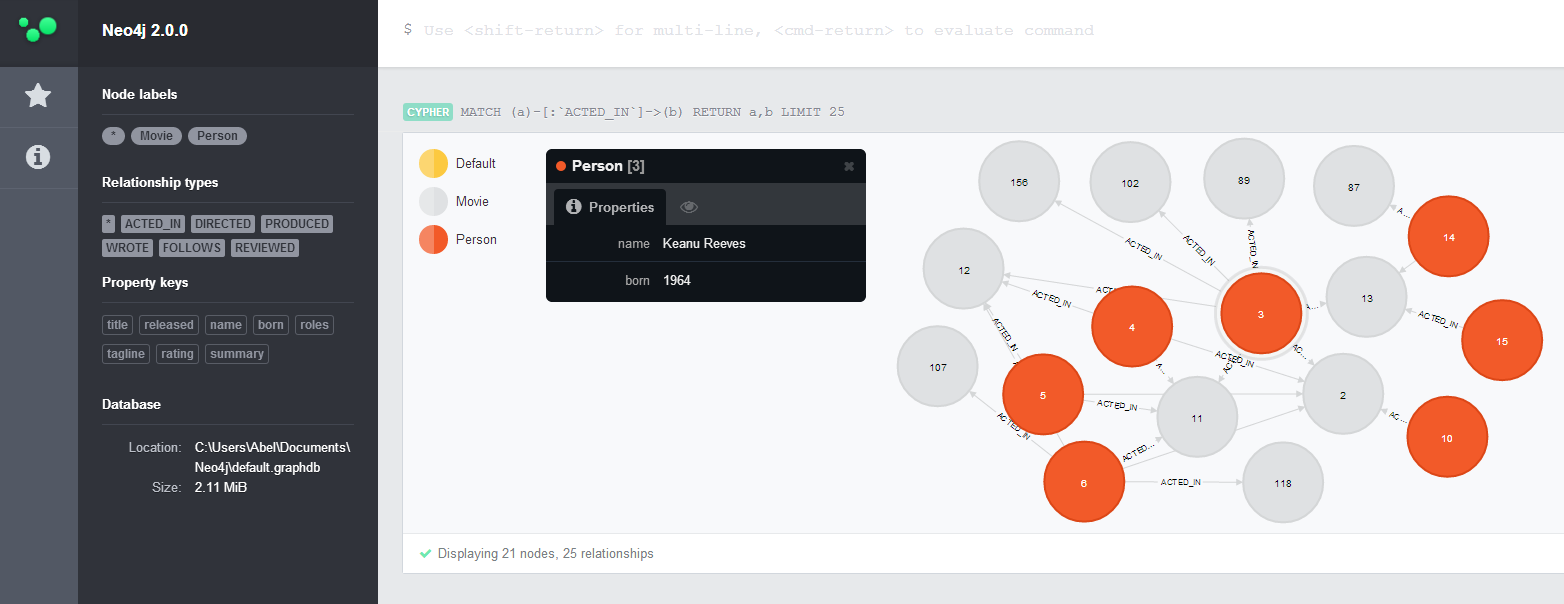
- Outil propriétaire, version gratuite disponible
- Facile à prendre en main par les équipes métier et informatique
- Large communauté, bien documenté
- Interrogeable avec Cypher, langage de requêtage propriétaire intuitif. Notons qu’il existe une alternative libre (OpenCypher)
- Gestion des contraintes : option payante et possibilités assez limitées
bémol : Le fait de ne pas imposer de contraintes sur les données offre des facilités de chargement appréciables. Cependant, le manque de contrôle pose des problèmes de type génération de doublons ou difficultés de réconciliation.
On relève un mode de fonctionnement efficace jusqu’à un certain volume mais la capacité de mise à l’échelle pose question.
En savoir plus :
Stardog (RDF*)
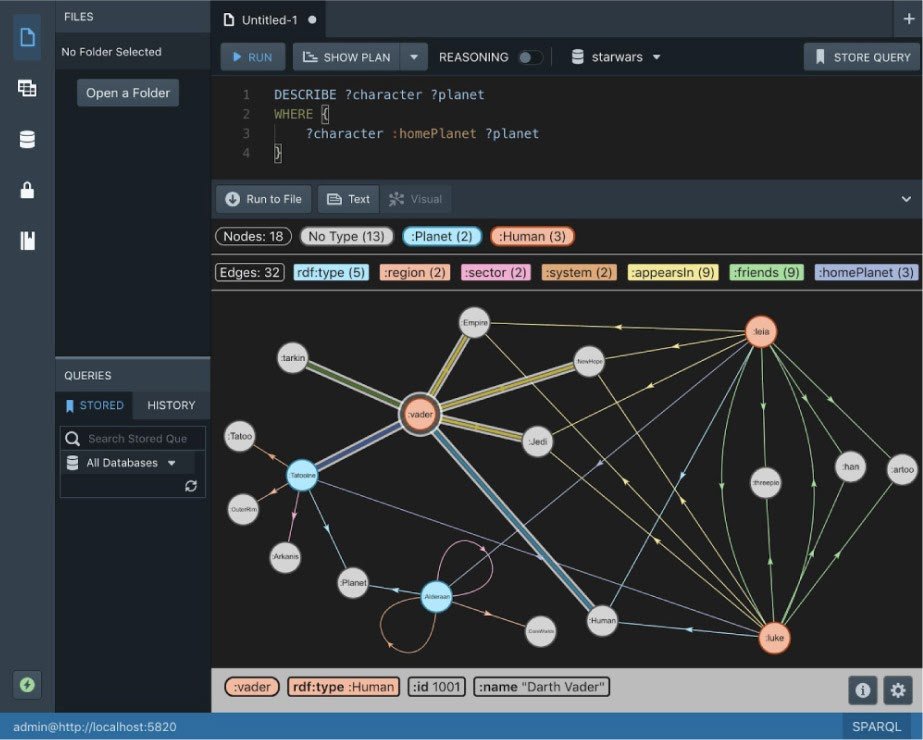
- Outil propriétaire, pas de version gratuite mais possibilité de disposer d’une version d’essai sur plusieurs mois
- Permet le stockage RDF natif
- Interrogeable en SPARQL
- Support très réactif lors de nos essais
- Références clients “grands comptes” : étude d’un cas d’usage similaire – Casalini Libri – mais avec une volumétrie moindre que le Sudoc
Les performances en écriture constituent un point de qualité important.
En ce qui concerne l’implémentation du stockage, Stardog exploite un moteur s’appuyant sur les Log Structured Merge Tree (LSM Tree), ce qui le rend capable de gérer la mise à l’échelle. Ce choix, basé sur RocksDB, facilite la gestion en clusters. On retrouve également cette fonctionnalité dans Dgraph, dont le moteur –Badger- offre une amélioration en Go possibles par rapport à RocksDB .
Pour la gestion des contraintes, l’éditeur annonce être compatible avec SHACL.
bémol : proposé dans les versions récentes, le support RDF* présente quelques imperfections à l’utilisation (standard en cours d’élaboration)
En savoir plus :
- Write Performance improves up to 500%
- Stardog in the storage wars
- Rocksdb mange régulièrement le monde des bases de données
GraphDB (RDF*) + Metaphactory
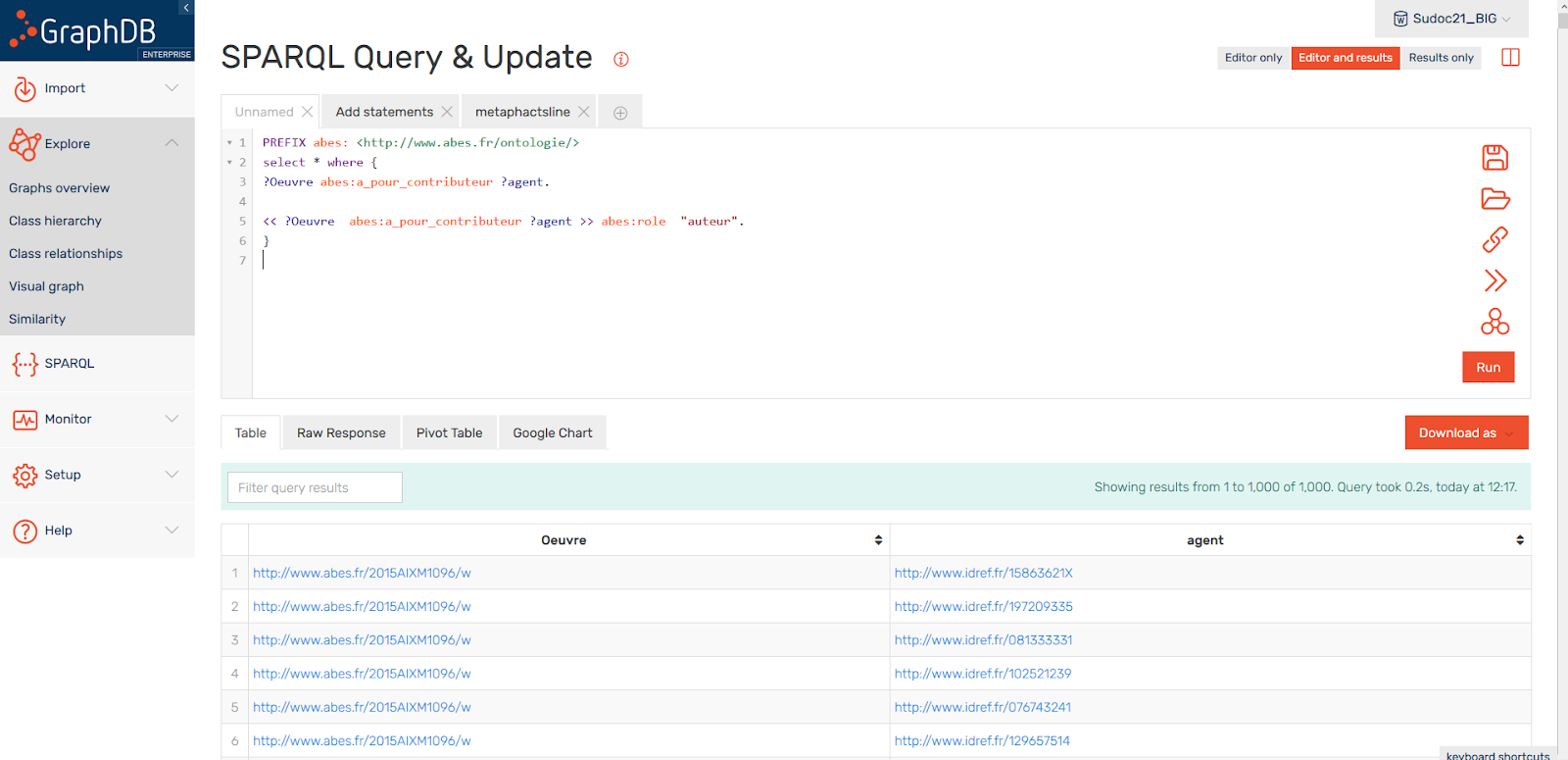
- Outil propriétaire
- Stockage en RDF natif
- Interrogeable en SPARQL
- Support de RDF*
- Facile à prendre en main, interface pratique et intuitive
- Possibilités de contraintes sur les données à l’aide de SHACL
Installé sur une instance GraphDB, Metaphactory permet la mise en place, sans code, d’interfaces utilisateurs comportant des outils de recherche poussés ainsi que des formulaires d’édition. Pour la visualisation des données (graphes, frises chronologiques, tableaux …), il met à disposition une large librairie de composants graphiques simples à implémenter. Cet outil propose également des API REST afin d’interagir directement depuis d’autres composants du système d’information.
A noter également qu’il est possible d’utiliser Metaphactory avec d’autres bases RDF. Il aurait par exemple été possible de le brancher à l’instance Stardog du projet.
bémol : nous nous sommes heurtés à des limites, dues principalement à l’approche “low code” et à une documentation peu fournie. Lorsque nous avons eu besoin d’adapter certains composants visuels, nous nous sommes aperçus qu’il pouvait être difficile d’effectuer des modifications importantes.
En guise de bilan, précisons que certains points – assez cruciaux – restent à évaluer sur ces nouveaux systèmes, et notamment :
- les performances en écriture sur de gros volumes
- la gestion transactionnelle : toute transaction nécessite la création de plusieurs nœuds et l’ajout d’arêtes entre ces nouveaux nœuds et ceux existants. Ces opérations doivent échouer/réussir comme une seule et unique modification. En effet, la gestion concurrentielle non bloquante est capitale pour ne pas impacter les performances sur des requêtes en écriture rapidement complexes.
- en savoir plus : Graph Update for One Event
3 – approche “mixte”
L’objectif qui sous-rend cette approche est d’exploiter la puissance d’un moteur relationnel sur les données, en bénéficiant des progrès sur les types de données en JSONB, tout en étant conscient de leurs limites (ex : pas de statistiques pour le moteur d’optimisation). On bénéficie ainsi de véritables transactions (ACID) et de la souplesse d’un type « semi-structuré ».
Le diaporama ci-dessous expose le cheminement qui a mené à ce type de solutions :
AgensGraph / A Graph Extension for PostgreSQL
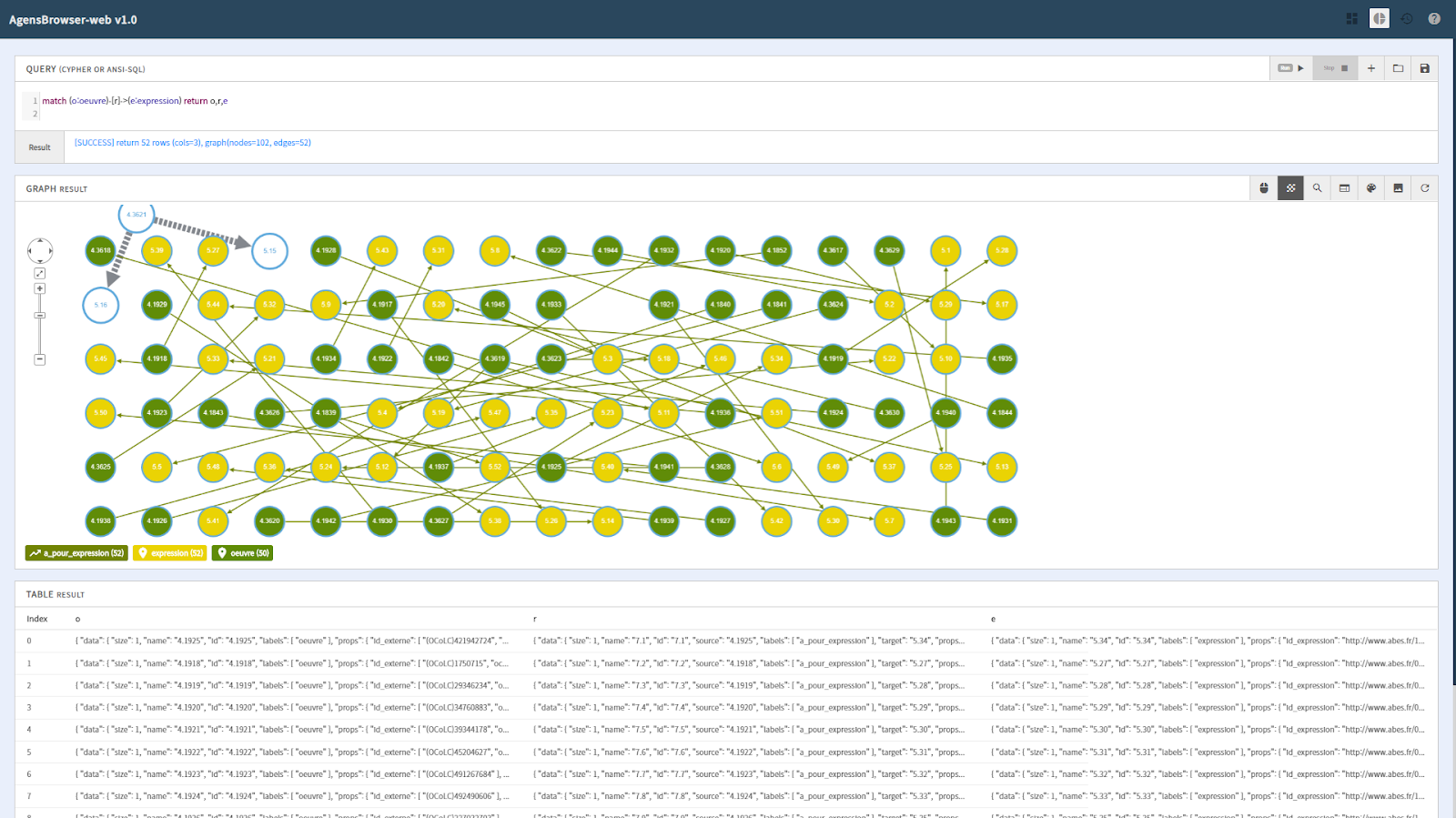
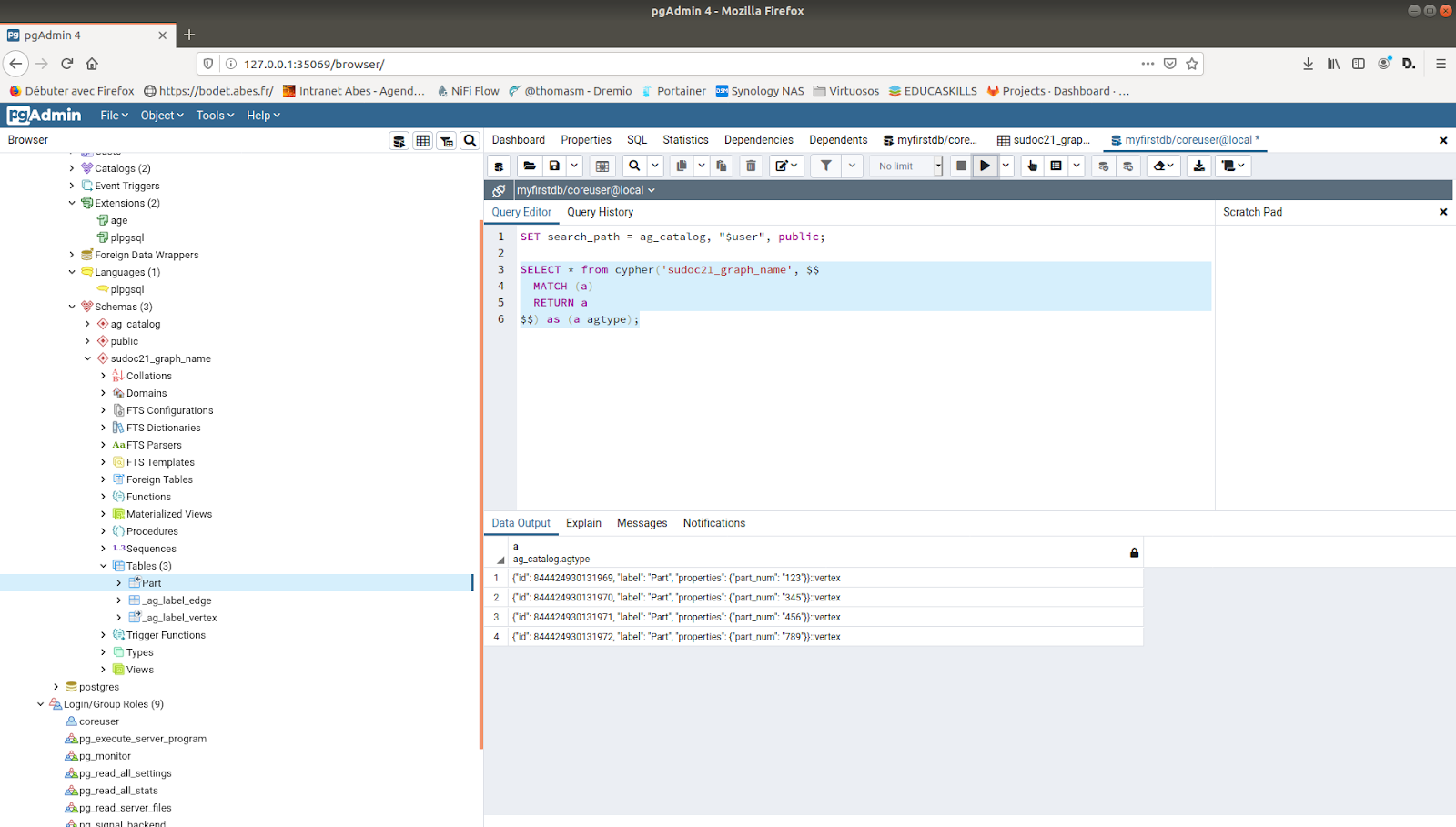
Cette solution technique, qui a l’avantage de gérer des graphes en open source, reprend plusieurs éléments : données structurées en JSONB, possibilité de jointures avec des tables relationnelles – par exemple pour les données d’usage ou les données de métriques. Précisons que cette solution récente, non stabilisée ayant émergé initialement dans la sphère asiatique, peu étudiée pendant l’expérimentation, est devenue un projet Apache actuellement à l’étude.
- Supporte OpenCypher
- Permet de mélanger des requêtes hybrides Cypher et SQL relationnel (PostgreSQL)
- PostgreSQL bénéficie d’un stockage transactionnel éprouvé auquel les équipes de Bitnine ajoutent un nouveau type d’index développé spécifiquement pour la gestion des sommets du graphe.
- Support du multi-valeurs (tableaux JSONB = liste ordonnée) : « subfields »: [7, 0.7, true, null, [« nested »], {« p »: « nested »}]
Quelles perspectives ?
Malgré le temps et les moyens impartis au projet, différentes questions restent à résoudre, et notamment celle de l’historicisation (versioning) des données. Par ailleurs, plusieurs points ne sont pas tranchés : quelle granularité ? quelle gestion pour les “retours en arrière” (commit/rollback) ?
Sachant que certaines techniques de réplication ou audit permettent de suivre le “delta” de données entre deux dates (ce qui répond à une partie du problème), on peut l’envisager comme une première piste de la gestion de l’historique, comme mentionné dans le rapport :
“On peut imaginer que la base de production est dupliquée. Dans la base dupliquée, la fonction d’audit transforme un journal de transaction propriétaire (WAL –Write Ahead Log) en des tables SQL exploitables et interrogeables. Le fait d’avoir ces tables dans une copie de la base permet de ne pas ralentir la base de production lorsqu’on exploite ces données de différentiel.”
Si on reprend les trois points d’évaluation évoqués au début de ce billet, on est tenté de conclure que les solutions de type « graphes/RDF » sont avantagées, car proches de la façon « humaine » de concevoir, modéliser, interroger.
Au final, les courbes d’adoption et la pérennité de ces nouvelles générations de solutions de stockage constituent les principaux reproches qui leur sont adressés en comparaison de la fiabilité des solutions relationnelles classiques en place depuis des années. On notera cependant que, pour les solutions “mixtes”, les acteurs historiques du monde du stockage relationnel proposent aujourd’hui une gestion « flexible » et efficace de ce type de données.
La question du choix technique reste donc ouverte. En effet, déterminer le “bon produit pour le bon usage » devra passer par l’analyse incontournable de la gestion de la volumétrie et de l’aspect transactionnel, autant d’éléments allant au-delà du périmètre du projet Sudoc21, dans son volet “Preuve de Concept”.
Ping : Les données en diptyque : exercice d'apagogie négative [2-2] - PUNKTOKOMO
Ping : Les données en diptyque : le noyau de la cerise ou la culture du pivot [2-1] - PUNKTOKOMO
Ping : Nom de code Sudoc21 - PUNKTOKOMO
https://bitnine.net/blog-agens-solution/blog-agensgraph/announcing-agensgraph-2-5/