

Afin de faire face au volume croissant d’informations qu’engendre l’évolution constante des métiers et des technologies, l’Abes relève de nombreux défis. L’un d’entre eux consiste dans le besoin de gérer les flux de grandes quantités de données entre diverses applications, de manière fiable et en temps réel.
Pour y répondre, le Service Urbanisation et Pilotage Informatique (SUPI) a mis en place un démonstrateur basé sur la solution Apache Kafka, solution informatique également utilisée par des collègues de la communauté de la documentation et en particulier par Swissbib et par l’INA avec qui l’Abes a échangé à plusieurs reprises.
Kafka : définition
Bien connu dans le monde de l’informatique, Kafka fait partie de la famille des bus de messages. A noter que dans cette famille, nous retrouvons les outils suivants, chacun ayant quelques nuances : RabbitMQ, ApacheMQ, ZeroMQ, Redis.
Plateforme logicielle développée en open source par la fondation Apache (Apache Software Fundation), Kafka est accessible à l’adresse suivante: https://github.com/apache/kafka
Initialement créé afin de répondre aux besoins de la plateforme LinkedIn, Kafka est conçu pour centraliser le stockage, le traitement et la transmission de « messages » constitués de données produites par diverses applications.
Toutes les fonctionnalités sont fournies de manière distribuée, évolutive, tolérante aux pannes et sécurisée sur des clusters (groupe de serveurs). Ainsi, Kafka garantit que la bonne information soit au bon endroit, au bon moment pour être mise à disposition des applications qui en ont besoin.
Kafka : les protagonistes
Pour comprendre le fonctionnement de Kafka, il faut en connaître les différents acteurs :
- les producteurs (publishers) : ils sont le point d’entrée, ils émettent les données à traiter.
- les consommateurs (suscribers) : ils sont les points de terminaison, ils reçoivent les données et les utilisent.
- les streams : ils sont situés en partie centrale. Ils consomment des données venant des producteurs et les transforment à destination d’autres consommateurs.

Kafka optimise les échanges entre le consommateur et producteur. On parle de modèle de messagerie « publish/subscribe » (publier-s’abonner).
Kafka : démonstrateur
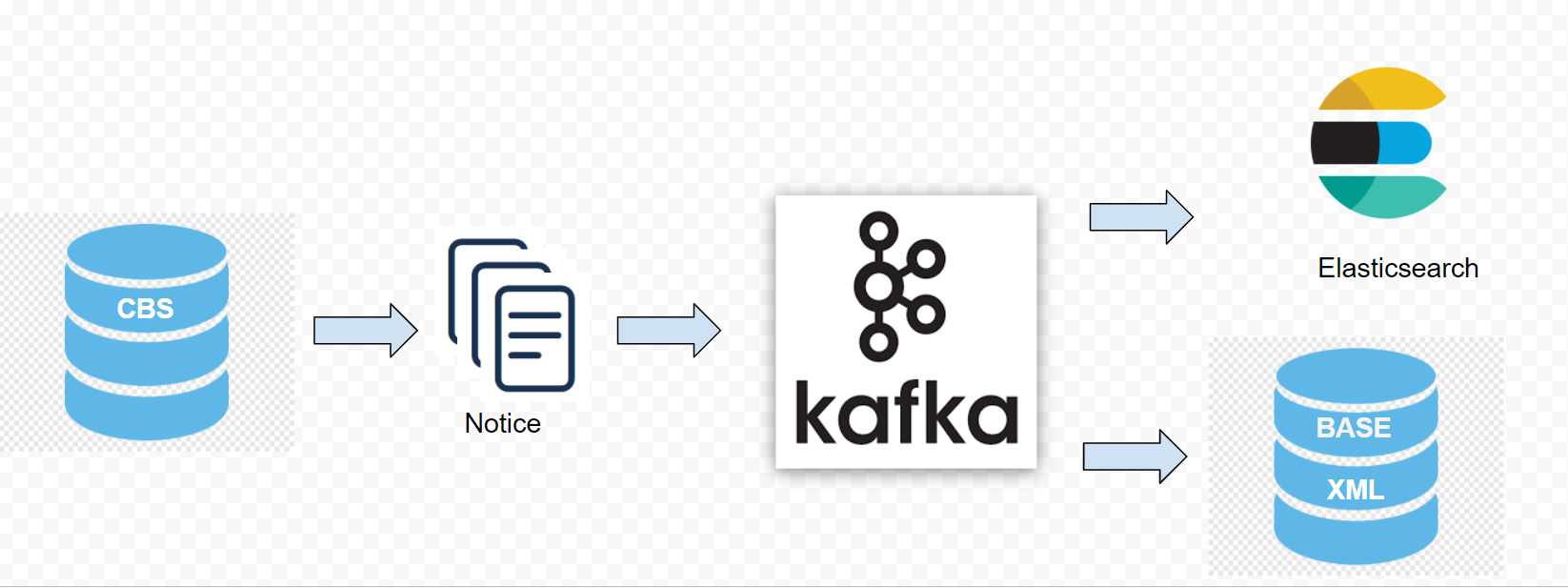
Notre démonstrateur concerne la base CBS – logiciel socle du Sudoc – avec ses notices au format MARCXML qui sont envoyées en tant que producteur dans Kafka dès qu’elles ont été modifiées ou créées, par exemple via l’outil WinIBW. Kafka les enregistre dans une file d’attente de messages ordonnés. Ces messages sont ensuite consommés par deux applications :
- un moteur de recherche ElasticSearch qui va indexer en temps réel les notices modifiées pour les mettre à disposition dans son moteur de recherche
- une base de données Oracle (nommée en interne « Base XML ») qui stocke la notice au format MARCXML et réplique ces données dans des tables SQL relationnelles pour une utilisation ultérieure par d’autres applications
Ces deux consommateurs sont avertis en temps réel lorsque de nouveaux messages sont produits.
Pour interagir par programme – dans notre cas avec Java – avec Kafka, les API suivantes ont été utilisées :
- API-producer : permet à un programme d’envoyer des données sur Kafka
- API-consumer : permet à un programme de s’abonner aux données préalablement envoyées dans Kafka
- API-stream : permet à un programme de fonctionner comme un «processeur de flux» en convertissant les flux d’entrée en sortie
Le démonstrateur a permis de vérifier les qualités de Kafka et notamment :
- la possibilité de s’abonner et de publier des données à travers nos applications
- le traitement en temps réel (Real Time Stream Processing) et à latence faible des flux de données qui arrivent dans son système
Ces fonctionnalités font de Kafka une véritable plateforme de diffusion (streaming) de flux de données.
En répondant à ces besoins spécifiques (modèle de messagerie publish/subscribe, traitement en temps réel), différents cas d’usages de Kafka sont envisagés par l’Abes :
- garder une ou des bases de données synchronisées avec un ou des moteurs de recherche chargés d’indexer tout ou partie de ces mêmes données
- faciliter le suivi des activités et de collecte de métriques à partir des échanges de données entre les applications.
- découpler les dépendances applicatives afin de réduire la charge sur certaines bases de données
- effectuer des intégrations, explorations ou visualisations de données volumineuses avec des technologies du Big Data (comme Spark, Hadoop, Flint …)
Pour compléter le travail du SUPI sur l’architecture de microwebservices mise en place en 2021, la prochaine étape consistera en l’intégration de Kafka. Il s’agira aussi de tester les limites de ce dernier afin de confirmer sa qualité de tolérance aux pannes.
Ainsi, cette brique contribuera à la transformation du Système d’Information de l’Abes permettant le traitement de volumes de données grandissants, en temps réel, et s’appuyant sur des outils issus de l’état de l’art.